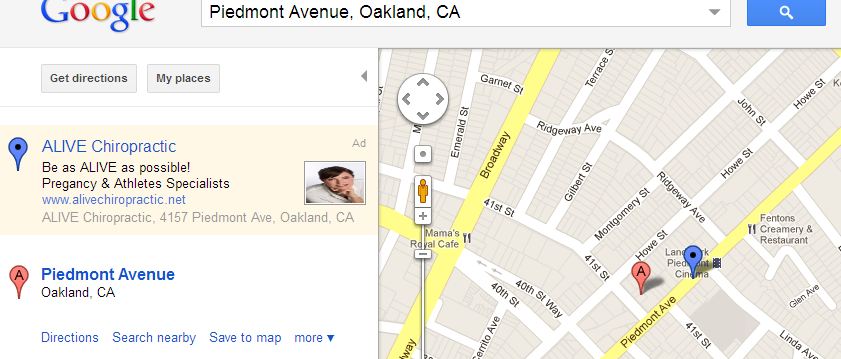
Google Maps, now with billboards
This is the first I’ve noticed location-specific ads being inserted into a google search. It makes sense that their map becomes a revenue source. If the ads don’t work, the the map will go away. It’ll be interesting to see how this plays out.
Category: Technology
Google-
I was searching for something random on Google (no, not that, regular expression examples) and noticed that funny little bar they put up there a while back when Google+ had the world all a-flutter. My little box had a [1] in it. Hmmm.. A few people I’d never heard of had “circled” me. Nobody I knew. I think I last checked G+ a few weeks ago, maybe it was a month. Oh well, so much for that one. Facebook will eventually do a MySpace, taking everyone’s cleverly crafted content out with it, but G+ won’t be the Facebook that does it. Or something like that.
Typing of Google, anyone else notice that Google has become much more aggressive about implicit substitution? I’m used to it autocorrecting typing, which actually led to ever more lazy typing, at least on my part. But I thought it always let me know when it was making a presumptive change. Search for [Congres] (using square brackets to denote the text box since “” has meaning in this context) and it used to note “Do you mean “Congress”” Yeah yeah, just fat-fingered the last letter, NP. Now it just silently corrects unless you use quotes. Maybe you actually wanted to find the “Hotel Du Congres.”
OK, annoying, but not fatal. But what is actually quite tedious is when you search for something slightly esoteric like [“white screen of death” client certificate]. 122,000 results. Whee. Oh, wait, most have nothing to do with client certificates – how can that be? [“white screen of death” “client” “certificate”] yields 367 results, almost all relevant. So for about 121,000 results Google assumes I just accidentally typed “client” and/or “certificate”? Those do not seem like common typos for [ ] (blank). If I went to all the trouble of typing out the words “client” and “certificate” does it not generally undermine the utility of a search function if it arbitrarily decides to ignore any inconvenient terms?
I find my self quote-forcing ([“white screen of death” +client +certificate] yields the same 367 results) most of my searches. Since when did my search terms become optional? WTF Google? Search is the one thing you do well. Well, that and advertising. Please don’t break it. Trust me, if you blow search you are not going to make up the difference with Social Networking.
Update: I recently searched for a scholarly article to back an assumption that document collections stored in structured databases can be accessed faster than document collections stored in file systems. I used the word “median” rather than “average” in my search, but clever Google knows the two are often synonyms and rather than limit my search to documents that use the typically academic “median,” I got almost entirely useless results referencing various colloquial “average” constructions.
Category: Negative • Reviews • Technology

Managing (lots of) Digitial Pictures
This is an older method, I do a lot of this with DigiKam now on Linux.
Over the decades, I’ve taken a lot of digital pictures. I was a bit haphazard in backing them up to CDs to random hard disks etc – meaning several copies. Over the years, bit rot has corrupted some copies, CDs from 20 years ago have started to go blank etc. Once I put together a ZFS 6 FreeNAS box, I thought it would be a good place to organize them, especially once I started playing with Picasa’s face recognition tool, which is awesome for reminding me who some of those people are in those old .jpgs staring back through the bit flip block defects of the ages.
I’ve tried a couple of face recognition tools – Microsoft’s, some other thing that really sucked, and Picasa, and Picasa’s is by far the best. Unfortunately Picasa suffers horribly from Google Hubris, that infuriating disease that renders otherwise excellent technologies almost unusable. An example many people have run into is Google’s idiotic threading model in gmail. They’ve decided that all messages are non-hierarchical blobs, that the meta information means nothing, and that we should trust the lucky feeling. If the messages Google chooses to show us aren’t what we were actually looking for, then we are doing it wrong.
Picasa is infected with the same disease, but has it even worse. Picasa has one uniquely good trick, it tags faces fairly well. It is not a particularly good tool, certainly not the best, for many other tasks people do with images. But since failing to recognize that the only right way to do any of these tasks is with Picasa, and really failing to understand that anything anyone would legitimately ever actually want to do with a digital image falls into the set of features Picasa has (or it is not legitimate), the fact that touching your images with any other program corrupts Picasa’s database and, entertainingly, wipes out any work that you’ve done with Picasa is, as reiterated over and over by Google’s reps in the Picasa forums, just proof that you’re doing it wrong.
And, of course, Google and Picasa will be with us forever, just like every image management and editing application that I was using back in 1990 when I started taking digital photos.
My little image collection, once fully deduplicated, is 52,000+ images and 122 GB of data, which I think crosses most predictable size fail thresholds, so if these tools work here, they should be pretty reliable for most people. If you don’t get it yet, and still fail to adhere to the Google Way, the following utilities aided my heresy.
Face Tagging (Fix Picasa with AvPicFaceXmpTagger)
If it wasn’t for the face tagging feature, I’d never use Picasa. I can’t wait until somebody competent writes a face tagging application that is as well written, straight forward, and standards compliant as Friedemann Schmidt’s GeoSetter – a gold standard in image utilities matched only by Irfan Skiljan’s IrfanView. Until then, there is, alas, only Picasa.
With a large collection of images, especially those with crowd shots, one quickly discovers that even Picasa’s devs haven’t through through the UI very well yet: there’s no way to reject large groups of pictures. It is also very tedious to work in manual mode: you can’t add faces in the “identify unknown faces” mode where you’d want to, for example. Another odd artifact is that to move a misidentified collection of faces to the right name, you have to select from a text-only popup list that quickly spans several 1200 pixel screens as you add names. If you type the first letter of the name, it jumps to it, but the scroll wheel doesn’t scroll the list and if you start typing the second letter of the name thinking you’ll get to the one you want (a standard UI reflex) you instead jump around to names beginning with that letter – but bonus feature – if you have only one person in the list who’s name begins with that letter, the reassignment executes automatically, which can make it hard to find where the pictures even went.
If it were me, I’d add an “indicate face” mode where I can indicate with just a click (not click, drag, name each time) where a face is and trigger a “look harder” iteration of the detection algo. It would also be useful to hint to the algo that a folder of images has more faces than already detected, try again. The algo should use meta information to aid in narrowing – for example certain faces tend to appear in different periods of one’s life. A good example might be taking a vacation with a friend: in that folder, everyone who kind of looks like the friend is more likely to be so. That is, look at frequency of appearance by metadata cluster and weight accordingly where metadata might be folder, file naming structure, GeoIP, date, time, etc.
But the huge problem with Picasa is that for reasons that could only make sense to a company that is absolutely, religiously certain they know the one and only true way to do anything correctly, Picasa writes the face ID information to a contacts.xml file, not using standards-compliant XMP face tagging. This means that when your picasa database gets corrupted (and it will, regularly) most of your face tagging efforts are lost if you don’t use a utility to write the face tag data to the EXIF meta information so it stays with the picture.
Fortunately, there is a tool to do just that: Andreas Vogel’s AvPicFaceXmpTagger. This utility will read the contacts.xml file and write the data into the image files as XMP compliant tags so the work will stay with your images. I ran it on my entire pre-deduplicated collection before deduplicating, and while it took about 20 hours, it did not barf.
What is particularly annoying is that the face detection algorithm is actually quite good, it is the database management that is beyond useless. Google has no excuse for being bad at information management. The meta information being attached to a picture couldn’t be easier – a name and coordinates. The contacts.xml file is intolerably fragile and completely tied to Picasa.
GeoTagging (Use GeoSetter)
Picasa used to be my geotag program, but then I found GeoSetter, and I completely abandoned Picasa’s inferior geotagging features and never looked back. It is now just a face recognition tool. It pretty much sucks at managing the data, and while AvPicFaceXmpTagger fixes the inexcusable shortcoming of not writing XMP tags with the face data, as soon as there’s a GeoSetter-quality, XMP-compliant face tagging solution, Picasa is so voted off the hard disk.
GeoSetter uses map integration to make tagging pictures easy, but it does The Right Thing, that is it puts as tags hierarchical place and altitude information as tags. Oddly, Picasa reps argue that geotags don’t do that any more, that is they only put the lat/lon into the picture assuming that the user will always be connected to Google’s servers and look up additional metadata from the lat/long as needed, arrogant, self-centered morons that they are. Real world users that don’t live on the Google campus still interact with their image data when their not connected to the interwebs, as difficult as this would be for Google to understand and as contrary to their plans for world domination as it is.
But Geosetter does it right, so don’t bother geotagging with Picasa. Geosetter will also look up the additional place name metadata based on lat/lon data in the picture and write that to the appropriate EXIF fields. It is powerful, easy to use, and very reliable.
Folder Organization (Organize folders by date with AmoK Exif Sorter)
Organizing pictures is highly subjective and there’s no right way – well except Picasa’s One True Way, but if your read this far, you’re probably not drinking that cool-aide. I, personally, like YYYY/YYYY-MO/YYYY-MO-DY/Image name folder structures. I, personally, don’t end up with more than 3-400 images in any single folder that way (and that very rarely) so OS’s don’t ever barf on a 20,000 image folder and it is fairly easy to find pictures. The tool I use to organize into year/month/day folders is AmoK Exif Sorter, which can read the EXIF create date and move images into my favorite folder structure automatically. It is a little slow on large folders of more than 2-3,000 images, but it didn’t fail on 20,000 images and sorted them all perfectly.
This works well because I use the same image organization with my EyeFi card, which transmits images directly from my camera to my laptop via wifi and sorts them as it goes. Everything prior to getting the card was randomly sorted until Exif Sorter fixed it, but now it should stay in sync. I really like my EyeFi card, but if upload is enabled when I am not in range of a discoverable network, the card sometimes crashes and I lose the last couple of pictures taken. I’m not happy about that, but I usually remember to turn upload off from the camera interface, and it has only made me really sad a few times so far.
DeDuplication (AntiTwin and DupDetector)
If you’re as disorganized as I am then you’ll ultimately end up with quite a few extra copies of your images as the years go by. Some of my collections had more than 10 copies in the nearly two decades since I first took them. I actually use two tools for deduplication: AntiTwin and DupDetector; I tried Picasa’s deduplication tool but it sucks and it isn’t clear that it is actually removing duplicates, rather just faking you into doing work with it that will later be lost when you have to reinstall Picasa in a few days after the database gets corrupted again (see rotation, below).
I do first pass deduplication with AntiTwin and use the byte by byte comparison at 100% match to find bit-for-bit copies. This does not detect copies with different EXIF tags (which happens) or images that are scaled for email and cluttering up your disk along with their original resolution master images, but you can be confident you’re not going to lose anything. I directly delete the copies AntiTwin finds. AntiTwin also has an image compare function, but it is useless on a large image collection.
To find scaled copies, copies with exif info, copies with minor bit rot, etc that AntiTwin won’t find, I use Prismatic Software’s DupDetector. I’ve found an odd mix of versions on download sites, and the author site is very slow, but it isn’t too huge and it works very well and has been recently updated. I use it to move, not delete copies, into a dead storage folder. If I make a mistake, the copies are still there, but I don’t need to have them in my primary search path. I am fairly confident that everything detected as a duplicate with match at 99.9% was actually a duplicate, but at 99.7%, it turned up some icon sized scaled pictures along with a lot of false matches in very dark pictures. I suggest first running at 100% in fully automatic mode, then cautiously at 99.9% in fully automatic mode; I only had 420 detected duplicates at 99.7%, and about half of those were true duplicates, so I ran at 99.7% in semi-auto mode.
Rotation (IrfanView)
One of the last steps for me is orienting all of my pictures upright using a JPEG Lossless rotation. In yet another facepalm move, Picasa fakes you out with rotations – it does not actually rotate the image, it just stores your rotation specification in picasa.ini file in the folder, which only Picasa uses, and that’s only until that file gets hosed for some reason. So if you spent a couple of days scrolling through the giant list of all your images rotating them one by one in Picasa, you wasted your time. Sorry. Thank Google.
Fire up IrfanView, load a directory of images, or even all subdirectories, and you can autorotate a giant library according to EXIF information. If your pictures go back more than about 5 years, your camera probably didn’t have an orientation sensor, so auto-rotate wont work. But Irfan’s thumbnail mode lets you select a few thousand images that need to be rotated the same way on by one (but quickly) and batch rotate them all losslessly.
If you do this, Picasa will still apply the picasa.ini rotation you created and it will be wrong, which is a good reminder not to use Picasa for anything any other program does better.
Category: photo • Positive • Reviews • Technology
Will G+ Eat RSS, or Insist on Sole Ownership?
Weird: I have yet to find a way to import an RSS feed into G+. This is one of those things that significantly undermines Google’s “your data” cred. Anyone know of a way to do it? I haven’t found an “import RSS feed into your feed” the way facebook kinda does and the wordpress/facebook plugin does.
I’m a very strong believer in “he who owns the hardware, owns the data,” so, for example, posting this on G+ means that this text is Google’s (note, this was originally published on G+, but G+ cratered proving the cloud is ephemeral and public,, then I stole it back!). And since it didn’t originate on my personal wordpress installation (free as in speech, free as in beer) running on my server at home (free as in speech, not absurdly expensive as in cheap beer), it isn’t mine.
My server also runs my mail server, my file server, my web server etc. all from my garage meaning that’s my data and my hardware and fully protected by law, while any data on Google’s server is effectively shared with every good and bad government in the world and my only legal recourse if it gets hacked or stolen or sold or given away or simply deleted is to… write an angry post on my blog and swear never to trust a cloud service again.
This is, obviously, exactly the same at FaceBook and every other cloud service. I use Facebook as a syndication service: I post on my own servers and syndicate via RSS to FaceBook, which becomes, in effect, the most frequently used RSS reader should people who haven’t gotten around to blocking me in their streams might find and by which perhaps occasionally be amused. This means I still own my data and my data has no particular dependence on FaceBook’s survival.
This post is visible only as long as Google wants it to be. If Google changes the rules, I lose the data. OK, I can download it – as long as they choose to let me, but it isn’t my data. When I post on my server then give FaceBook permission to republish the data, I control my data and they get only what I decide to give them. When I post this on Google and then ask “please, sir, may I recover my post for another use?” the power relationship is reversed: Google owns and controls everything and my rights and usage are only what they deign to offer me.
That almost everyone trusts the billionaire playboys who put king sized beds in their 767 party plane as “do no evil” paragons of virtue is odd to me, but nothing better validates Erich Fromm’s thesis than the pseudo-religious idolatry of Google and Apple. Still, even the True Believers should realize that the founders of these Great Empires are not truly immortal and that even if Google is doing no evil now, it will change hands and those that inherit every search you’ve ever done, every web page you’ve ever visited, every email you’ve ever sent, every phone call you’ve ever made or received, the audio of every message ever left for you, the GPS traces of every step you’ve ever taken, every text and chat and tweet might think, say, that Doing Good means something different than you think it does. One should also remember the Socratic Paradox that renders tautological Google’s vaunted motto.
Unfortunately, at least so far, Google won’t let me use G+ to syndicate my data – they insist on owning it and dictating the terms by which I can access it. If I want to syndicate content through my G+ network, it seems I have to fully gift Google that content. I’m hoping there’s a tool to populate my “posts” from RSS so the canonical will remain on my server. Because it is the Right Thing To Do.
(Shhhh.. I’m going to copy and paste this into my own wordpress installation, even though I wrote it here on the G+ interface. They probably won’t send me a DMCA takedown, but I do run the risk that they’ll hit me with a “duplicate content penalty” and set my page rank to 0 thus ensuring nobody ever finds my site again. Ah, absolute power, so reassuring to remember that it is absolutely incorruptible.)
Category: Politics • Self-publishing • Technology
FB vs. G+
An interesting artifact of the FB vs. G+ debate is the justification by a lot of tech-savvy people in moving to G+ from FB because they believe Google to be less evil. It is an odd comparison to make, both companies are in essentially the same business: putting out honey pots of desirable web properties, attracting users, harvesting them, and selling their data.
Distinguishing between grades of evil in companies that harvest and sell user data seems a little arbitrary. I’d think it would make more sense to use each resource for what it does well rather than arbitrarily announce that you’re one or the other.
However, if one is making the choice as to what service to call home on the basis of least “evil” and assuming that metric is derived in some way from the degree to which the company in question harvests your data and sells it, then it is somewhat illuminating to look at real numbers. One can assume that the more deeply one probes each user captured by the honey pot, the more data extracted, the more aggressively sold, the more money one makes. The company that makes the most money per user is probing the deepest and selling the hardest.
From Technology Review May/June 2011, annual revenue per monthly unique US visitor:
Facebook: $ 12.10
Google: $163.60
Google squeezes out and sells more than 13.5x the data per user. Google wins. But Facebook is gathering $12.10 worth of user data, why should Google allow Facebook to have it? If Google wins that last morsel of data to take to market and takes out Facebook, Google can increase their gross revenue by 7%.
I’ve also heard people argue that Zuckerberg seems more personally avaricious, mean, or evil than Google’s founders, comparing Google’s marketing spin to “The Social Network”
Zuckerberg’s only newsworthy purchase was a $7m house in Palo Alto. Google co-founders were in the news over a lawsuit between them over whether their 767 “party plane” (Eric Schmidt) could house Brin’s California king bed. This is in addition to their 757 and two Gulfstream Vs they talked NASA into letting them park at Moffet under the pretense that the planes would be retrofit with instruments for NASA. When they couldn’t do that (FAA regs, who knew?), they bought a Dornier Alpha, but still get to park their jumbo jets and gulfstreams inside NASA hangers for some reason. Suck on that, Ellison!
Category: Technology • Vanity sites
Moar Privacy
I’m using an Ubuntu VM for private browsing, and like many people, I’m stuck using a mainstream OS for much of my work (Win7) due to software availability constraints. But some software works much better in a linux environment and Ubuntu is as pretty as OSX, free, and installs easily on generic x86 hardware.
It is also pretty straightforward to install an isolated and secure browsing instance using VirtualBox. It takes about 20G of hard disk and will use up at least 512K (better 1G) of your system RAM. If you want to run this sort of config, your laptop should have more than enough disk space and RAM to support the extra load without bogging, but it is a very solid solution.
Installing Ubuntu is easy – even easier with an application like VirtualBox – just install virtualbox, download the latest ubuntu ISO, and install from there. If you’re on bare metal, the easiest thing to do is burn a CD and install off that.
Ubuntu desktop comes with Firefox in the tool bar. Customizing for private browsing is a bit more involved.
My first steps are to install:
- noscript to create your own whitelist of sites allowed to run scripts,
- better privacy to apply rules for deleting flash cookies,
- TACO to control tracking cookies,
- UserAgentSwitcher to make your ubuntu/firefox rig generic looking,
- Tor Button to browse without leaving a trail of your IP address.
NoScript is an easy win. It is a bit of a pain to set up at first, but soon you add exceptions for all your favorite sites and while that isn’t great security practice, it is essential for sane browsing. NoScript is particularly helpful when browsing the wacky parts of the net and not getting exotic browsing diseases: it is your default dental dam. Be careful of allowing domains you don’t recognize – Google them first and make sure you understand why they need to run a script on your computer and that it is safe. A lot of sites use partners for things like video feeds, so if some function seems broken, you probably need to allow that particular domain. On the other hand, most of the off-site scripts are tracking or stats and you really don’t need to play along with them.
BetterPrivacy is a new one for me. I am very impressed that it found approximately 1.3 zillion (OK 266) different company flash cookies AFTER I had installed TACO and noscript etc. You bastards. I’m sure I can enjoy hulu without making my play history shared-available to every flash site I might visit. Always Sunny in Philadelphia marks me as a miscreant. I flush the flash cookies on starting silently (preferences).
TACO is a bit intrusive, but it seems to work to selectively block tracking and advertising cookies. At least the pop up is comforting. For private browsing, I’d set it to reject all classes of tracking cookies (change the preferences from default).
User Agent Switcher is useful when you’re deviating from the mainstream. Running Ubuntu pretty much flags you as a trouble maker or at least a dissident. Firefox maybe a bit less so, but you are indicating to advertisers that you don’t respect the expertise of those people far smarter than you who pre-installed IE (or Safari) to make your life easier. Set your user agent to IE 8 because the nail that sticks up gets pounded down.
Torbutton needs Tor to work. Tor provides really good privacy, but is a bit involved. The Tor Button Plugin for firefox makes it seem easier than it really is: you install it and click “use tor” and it looks like it is working but the first site you visit you get an proxy error because Tor isn’t actually running (DOH!).
To get Tor to work, you will have to open a terminal and do some command line fu before it will actually let you browse. Tor is also easier to install on Ubuntu than on Windows (at least for me, but as my browser history indicates I’m a bit of a miscreant dissident, so your mileage may vary).
Starting with these fine instructions.
sudu gedit /etc/apt/sources.list
add
deb http://deb.torproject.org/torproject.org/ lucid main
deb-src http://deb.torproject.org/torproject.org/ lucid main
Then run
gpg --keyserver keys.gnupg.net --recv 886DDD89
gpg --export A3C4F0F979CAA22CDBA8F512EE8CBC9E886DDD89 | sudo apt-key add -
sudo apt-get update
sudo apt-get upgrade
sudo apt-get update
sudo apt-get install tor tor-geoipdb
Install vidalia with the graphical ubuntu software center or with
sudo apt-get install vidalia
Tor expects Polipo. And vidalia makes launching and checking on Tor easier, so remove the startup scripts. (If Tor is running and you try to start it from vidalia, you get an uninformative error, vidalia has a “launch at startup” option, so let it run things.) Vidalia appears under the Applications->Network.
sudo update-rc.d -f tor remove
Polipo was installed with Tor, so configure it:
sudo gedit /etc/polipo/config
Clear the file (ctrl-a, delete)
paste in the contents of this file:
UPDATE: paste in the contents of this file:
(if the link above fails, search for “polipo.conf” to find the latest version)
I added the binary for polipo in Vidalia’s control panel, but that may be redundant (it lives in /usr/bin/polipo).
I had to reboot to get everything started.
And for private chats, consider OTR!
Category: Politics • Technology
Testing Privacy Tools
I was curious after posting some hints about how to protect your privacy to see how they worked.
Using EFF’s convenient panopticlick browser fingerprinting site. Panopticlick doesn’t use all the tricks available, such as measuring the time delta between your machine and a reference time, but it does a pretty good job. Most of my machines test as “completely unique,” which I find complementary but isn’t really all that good for not being tracked.
Personally I’m not too wound up about targeted marketing style uses of information. If I’m going to see ads I’d rather they be closer to my interests than not. But there are bad actors using the same information for more nefarious purposes and I’d rather see mistargeted ads than give the wrong person useful information.

Testing Panopticlick with scripts blocked (note TACO doesn’t help with browser fingerprinting, just cookie control) I cut my fingerprint to 12.32 bits from 20.29 bits, the additional data comes from fonts and plugins.
Note that EFF reports that 1:4.1 browsers have javascript disabled. Visitors to EFF are, I would assume, more likely to disable javascript than teh norm on teh interwebz, but that implies that javascript-based analytics packages like Google analytics miss about 25% of visitors.

It is also interesting to note that fingerprint scanners (fingerprints as on the ends of fingers) have false reject rates of about 0.5% and false acceptance rates of about 0.001%. Obviously they’re tuned that way to be 50x more likely to reject a legitimate user than to accept the wrong person and the algorithms are intrinsically fallible in both directions, so this is a necessary trade-off. Actual entropy measures in fingerprints are the subject of much debate. An estimate based on Pankanti‘s analysis computes a 5.5×10^59 chance of a collision or 193 bits of entropy but manufacturer published false acceptance rates of 0.001% are equivalent to 16.6 bits, less accurate than browser fingerprinting.
Category: Politics • Technology
Opting Out for Privacy
There’s a great story at the wall street journal describing some of the techniques that are being used to track people on line that I found informative (as are the other articles listed in the series in the box below). EFF is doing some good work on this; your browser configuration probably uniquely identifies you and thus every site you’ve ever visited (via data exchanges). Unique information about you is worth about $0.00_1. Collecting a few hundred million 1/10ths of a cent starts to add up and may end up raising your insurance premiums.
One of the more entertaining/disturbing tricks is to use “click jacking” to remotely enable a person’s webcam or microphone. Is your computer or network running slowly? Maybe it is the video you’re inadvertently streaming back (and maybe you just have way too many tabs open…)
A few things you can do to improve your privacy include:
- Opt out of Rapleaf. Rapleaf collects user information about you and ties it to your email address. You have to opt out with each email address individually, which almost certainly confirms to them that all your email addresses belong to the same person. You might want to use unique Tor sessions for each opt out if you don’t want them to get more information than they already have via the process.
- Opt out at NAI. This is a one stop shop for the basic cookie tracking companies that are attempting to be semi-compliant with privacy requests. If you enable javascript for the site (which would be disabled by default if you’re using scriptblocker) then you can opt out of all of them at once. Presumably you have to return and opt out again every time a new company comes along.
- Use Tor for anything sensitive. If you care about privacy, learn about Tor. It does slow browsing so you have to be very committed to use it for everything. But the browser plug in makes it pretty easy to turn it on for easy browsing.
- Don’t use IE for anything personal or important.
- Run SpyBot Search and Destory regularly. Spybot helps block BHOs and toolbars that seem to proliferate automagically and helps remove tracking cookies. You’ll be amazed at how many are installed on your system. I have used or not used TeaTimer. I’m less excited about having a lot of background tools, even helpful ones than I used to be. Spybot currently starts out looking for 1,359,854 different known spywares. Yikes.
- Check what people know about you: Google will tell you, so will Yahoo. Spooky.
- Use firefox. If for no other reason than the following plugins (personally, it is my favorite, but I know people who favor chrome or even rockmelt, but talk about tracking!) Just don’t use IE.
- Use the private browsing mode in your browser (CTRL-SHIFT-P in FireFox). It’d be nice if you could enable non-private browsing on a whitelist basis for sites you either trust or have to trust. We’ll get there eventually…
- TACO should help block flash cookies.
- Install noscript to block scripts by default. You can add all your favorite sites as you go so things work. It is a pain in the ass for a while, but security requires vigilance.
- Install adblock plus. It helps keep the cookies away. It also reduces ad annoyance. You can enable ads for your favorite sites so they can pay their colo fees.
- Add HTTPS Everywhere from EFF. The more your connections to sites are encrypted, the less your ISP (and others) can see about what you’re doing while you’re there. Your ISP still knows every site you visit, and probably sells that information, but if your sessions are encrypted they don’t see the actual text you type. It also makes it harder for script kiddies to grab your passwords at the cafe.
Category: Politics • Privacy • Security • Technology
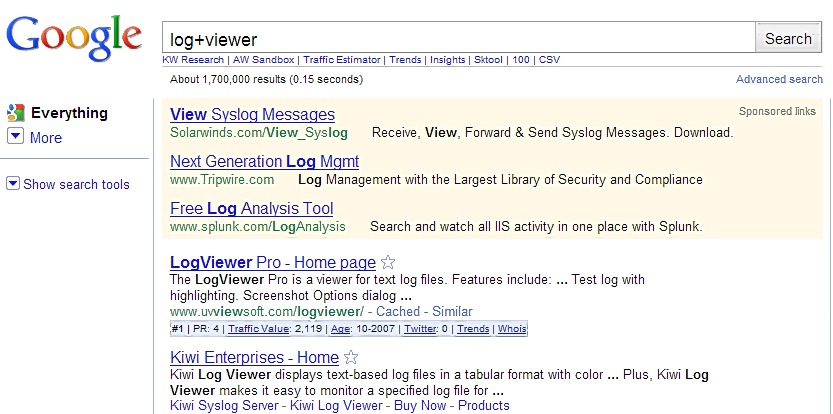
What up with the “+” Google?
<meta content=”text/html; charset=ISO-8859-1″
http-equiv=”Content-Type”>
Type “Log Viewer” (without the quotes) and get “Log+Viewer.” It seems
like an operator that would force adjacency, but it doesn’t seem to.
“Log AND Viewer” becomes “Log+AND+Viewer” (the explicit operator isn’t
parsed) and “”log viewer”” becomes “”log+viewer”” so it seems the space
is being replaced with “+” (#32 replaced by #43).
Category: Odd • Technology
-
Recent Posts
- Goodbye, Tortuga. 2024 April 25
- A one page home/new tab page with random pictures, time, and weather 2024 April 11
- Putting ccache on a backed RAM disk to speed compiles 2024 March 16
- Audio File Analysis With Sox 2024 February 07
- Manually Update Time Zone Data on Android 10 2023 October 31
- Autodictating to self using Whisper to preserve privacy 2023 August 17
- Projecting Qubit Realizations to the Cryptopocalpyse Date 2023 August 04
- AI PSYOPS are changing strategic messaging 2023 July 29
- Convert A Slideshow/Presentation into HTML 5 Video 2023 July 23
- Mobotix Notifier in Python – get desktop messages from your cameras 2023 June 06
- Categories
- Links
- Search
- Archives
- Post History