Google Inc.
Making Chrome Less Horrible
Google’s Chrome is a useful tool to have around, but the security features have gotten out of hand and make it increasingly useless for real work without actually improving security.
After a brief rant about SSL, there’s a quick solution at the bottom of this post.
Chrome’s Idiotic SSL Handling Model
I don’t like Chrome nearly as much as Firefox, but it does do some things better (I have a persistent annoyance with pfSense certificates that cause slow loading of the pfSense management page in FF, for example). Lately I’ve found that the Google+ script seems to kill firefox, so I use Chrome for logged-in Google activities.
But Chrome’s handling of certificates is abhorrent. I’ve never seen anything so resolutely destructive to security and utility. It is the most ill-considered, poorly implemented, counter-productive failure in UI design and security policy I’ve ever encountered. It is hateful and obscene. A disaster. An abomination. The ill-conceived excrement of ignorant twits. I’d be happy to share my unrestrained feelings privately.
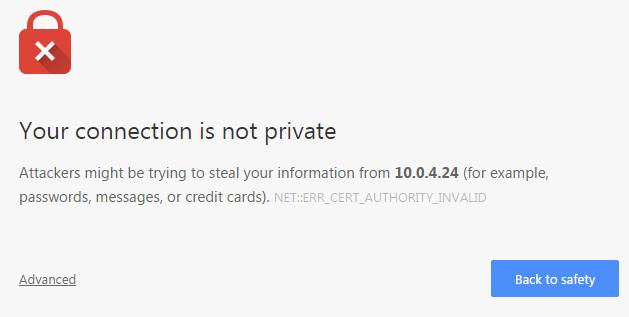
I’ve discussed the problem before, but the basic issues are that:
- The certificate authority is NOT INVALID, Chrome just doesn’t recognize it because it is self-signed. There is a difference, dimwits.
- This is a private network (10.x.x.x or 192.168.x.x) and if you pulled your head out for a second and thought about it, white-listing private networks is obvious. Why on earth would anyone pay the cert mafia for a private cert? Every web-interfaced appliance in existence automatically generates a self-signed cert, and Chrome flags every one of them as a security risk INCORRECTLY.
- A “valid” certificate merely means that one of the zillions of cert mafia organizations ripping people off by pretending to offer security has “verified” the “ownership” of a site before taking their money and issuing a certificate that placates browsers
- Or a compromised certificate is being used.
- Or a law enforcement certificate is being used.
- Or the site has been hacked by criminals or some country’s law enforcement.
- etc.
A “valid” certificate doesn’t mean nothing at all, but close to it.
So one might think it is harmless security theater, like a TSA checkpoint: it does no real harm and may have some deterrent value. It is a necessary fiction to ensure people feel safe doing commerce on the internet. If a few percent of people are reassured by firm warnings and are thus seduced into consummating their shopping carts, improving ad traffic quality and thus ensuring Google’s ad revenue continues to flow, ensuring their servers continue sucking up our data, what’s the harm?
The harm is that it makes it hard to secure a website. SSL does two things: it pretends to verify that the website you connect to is the one you intended to connect to (but it does not do this) and it does actually serve to encrypt data between the browser and the server, making eavesdropping very difficult. The latter useful function does not require verifying who owns the server, which can only be done with a web of trust model like perspectives or with centralized, authoritarian certificate management.
How to fix Chrome:
The damage is done. Millions of websites that could be encrypted are not because idiots writing browsers have made it very difficult for users to override inane, inaccurate, misleading browser warnings. However, if you’re reading this, you can reduce the headache with a simple step (Thanks!):
Right click on the shortcut you use to launch Chrome and modify the launch command by adding the following “--ignore-certificate-errors”
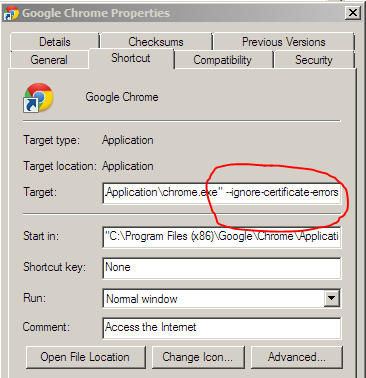
Once you’ve done this, chrome will open with a warning:

YAY. Suffer my ass.
Java? What happened to Java?
Bonus rant
Java sucks so bad. It is the second worst abomination loosed on the internet, yet lots of systems use it for useful features, or try to. There’s endless compatibility problems with JVM versions and there’s the absolutely idiotic horror of the recent security requirement that disables setting “medium” security completely no matter how hard you want to override it, which means you can’t ever update past JVM 7. Ever. Because 8 is utterly useless because they broke it completely thinking they’d protect you from man in the middle attacks on your own LAN.
However, even if you have frozen with the last moderately usable version of Java, you’ll find that since Chrome 42 (yeah, the 42nd major release of chrome. That numbering scheme is another frustratingly stupid move, but anyway, get off my lawn) Java just doesn’t run in chrome. WTF?
Turns out Google, happy enough to push their own crappy products like Google+, won’t support Oracle’s crappy product any more. As of 42 Java is disabled by default. Apparently, after 45 it won’t ever work again. I’d be happy to see Java die, but I have a lot of infrastructure that requires Java for KVM connections, camera management, and other equipment that foolishly embraced that horrible standard. Anyhow, you can fix it until 45 comes along…
To enable Java in Chrome for a little while longer, you can follow these instructions to enable NPAPI for chrome <42 (which enables Java). Type “chrome://flags/#enable-npapi” in the browser bar and click “enable.”

The Cloud is Ephemeral
Never trust your business, applications, or critical data to a cloud service because you are at the mercy of the provider both for security and availability, neither of which are terribly likely. Cloud services are the .coms of the 2nd decade of the 21st century, they come and go and with them so go your data and possibly your entire enterprise. Typically the argument is that larger brands are safer, that a company like Google would not wipe out a service leaving their customers or partners high and dry, that they would be safe.
That would be a false assumption.
It is necessary to understand the mathematics of serial risk to evaluate the risk-weighted cost of integrating a cloud-provisioned service into a business. It is important to note that this is entirely different from integrating third party code, which just as frequently becomes abandonware; while abandonware can result in substantial enterprise costs in engineering an internally developed replacement it continues to function, a cloud service simply vanishes when the provisioning company “pivots” or craters, instantly breaking all dependent applications and even entire dependent enterprises: it is a zero day catastrophe.
Serial risks create an exponential risk of failure. When one establishes a business with N critical partners, the business risk of failure is mathematically similar to RAID 0. If each business has a probability of failure of X%, the chances of the business failing is 1-(1-X/100)^N. If X is 30% and your startup is dependent on another startup providing, say, a novel authentication mechanism to validate your cloud service, then the chances of failure for your startup rise from 30% to 51%. Two such dependencies and chances of failure rise to 64% (survival is a dismal 36%).
Testing Privacy Tools
I was curious after posting some hints about how to protect your privacy to see how they worked.
Using EFF’s convenient panopticlick browser fingerprinting site. Panopticlick doesn’t use all the tricks available, such as measuring the time delta between your machine and a reference time, but it does a pretty good job. Most of my machines test as “completely unique,” which I find complementary but isn’t really all that good for not being tracked.
Personally I’m not too wound up about targeted marketing style uses of information. If I’m going to see ads I’d rather they be closer to my interests than not. But there are bad actors using the same information for more nefarious purposes and I’d rather see mistargeted ads than give the wrong person useful information.

Testing Panopticlick with scripts blocked (note TACO doesn’t help with browser fingerprinting, just cookie control) I cut my fingerprint to 12.32 bits from 20.29 bits, the additional data comes from fonts and plugins.
Note that EFF reports that 1:4.1 browsers have javascript disabled. Visitors to EFF are, I would assume, more likely to disable javascript than teh norm on teh interwebz, but that implies that javascript-based analytics packages like Google analytics miss about 25% of visitors.

It is also interesting to note that fingerprint scanners (fingerprints as on the ends of fingers) have false reject rates of about 0.5% and false acceptance rates of about 0.001%. Obviously they’re tuned that way to be 50x more likely to reject a legitimate user than to accept the wrong person and the algorithms are intrinsically fallible in both directions, so this is a necessary trade-off. Actual entropy measures in fingerprints are the subject of much debate. An estimate based on Pankanti‘s analysis computes a 5.5×10^59 chance of a collision or 193 bits of entropy but manufacturer published false acceptance rates of 0.001% are equivalent to 16.6 bits, less accurate than browser fingerprinting.