Microsoft Spyware Now Being Installed On Win 7
If you’re the sort of person who isn’t entirely happy about the idea of Microsoft claiming the right to copy your personal files, photos, emails, chat logs, diary entries, medical records, etc over to their own servers to sell to whoever they want for whatever they can get for your personal data – into markets that already exist for insurance companies to deny you insurance based on algorithmic analysis of your habits or your friends habits or for financial institutions to set your interest rates based on similar criterion, or perhaps even for law enforcement to investigate you without a warrant, then OBVIOUSLY you would never, ever install Windows 10 under any circumstances.
Well, Microsoft seems to have fully jumped on the Google/Facebook gravy train and is now completely invested in stealing your data and selling it to the highest bidder (Apple has been exfiltrating your data for a long time, but so far for internal use). I’ve become more suspect of Microsoft’s updates since they made the Windows 10 advertisement an important (not optional) update (important for what? their bottom line, obviously). Turns out that the latest updates to Windows 7 are pushing Microsoft’s new business model of stealing your data for profit to Windows 7 and 8.
Staying safe is going to require ever more vigilance. It may be possible to block windows components from reaching out to microsoft’s servers at the personal firewall level and certainly it can be done at the corporate firewall level (and should be), but blocking Microsoft is a somewhat complex issue. You can’t run Windows safely without installing security patches because the underlying OS is so completely insecure that new, critical, exploitable flaws are discovered every single week. If you don’t constantly patch these security failures, you will be hacked by people other than microsoft. If you install the wrong microsoft patch, you will be hacked by microsoft. Debian anyone? Also, software developers developing enterprise software, please, please, please stop developing for that horrible, insecure, performance hobbling abomination of a tarted-up single-user OS “Server” and focus on a secure, stable server OS like FreeBSD. Please. I hate, hate having to fork over $1k to microsoft for each box to run their horrible OS just so I can run your software. Why do you support that extortion? Do you despise your customers that much? Stop.
If you care about corporate governance and data security or HIPAA compliance, you are probably violating some critical requirements by installing windows 10 or these new updates to your existing Win7/8 base if you do not block data exfiltration to Microsoft’s servers. This is spyware. These updates are stealing your data and sending it to Microsoft. If your business is subject to data privacy laws, these updates put you in violation of those laws. Microsoft is doing something that is extremely significant and extremely evil and completely wrong. Take action or you may very well be facing personal or corporate consequences. srsly.
I am a strong believer in data privacy and extremely suspect of what I consider highly disingenuous business practices like Google’s but I recognize that there are reasonable people out there who think Google isn’t evil. However, this windows 10 issue, now being pushed to windows 7, goes well beyond Google taking advantage of people’s historical assumptions about the security of email to offer them a free look-alike honey trap to gather their data. Windows 10 and these Win 7 updates are intrusive, not merely misleading. Do not update. Srsly. Do not update. Block the spyware “hotfixes.”
- Russia considers banning windows 10
- Bit torrent trackers ban Windows 10 users
- Windows 10 steals so much data it breaks your data plan and costs you money
- Windows 10 is spyware, plain and simple, including a keylogger.
Stop Gap Fixes
In researching these updates, I came across this article on techworm that has a nice summary of the Malware updates Microsoft is pushing out (with some additional amendments I found):
- KB2952664 (this one reappears no matter how often you unselect it or hide it – so memorize it as evil)
- KB2976978
- KB2977759
- KB2990214
- KB3021917
- KB3022345
- KB3035583
- KB3044374
- KB3068708
- KB3075249
- KB3080149
- KB3112343
- KB3123662
- KB3123862 (new)
- KB3173040 NEW – “final” full screen nag advertisement for Win10 malware
With a whiff of irony, this google search “telemetry site:https://support.microsoft.com/en-us/kb” shows these patches and many more…
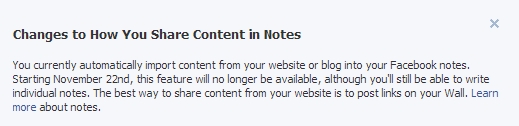
Do not automatically install Microsoft updates. You must turn that feature off or you will keep getting additional spyware installed. Go to windows update and verify your settings. I have mine set so windows downloads the updates (so the updates are waiting locally), but I don’t let windows install them automatically. That gives me a chance to review the updates and look for spyware.
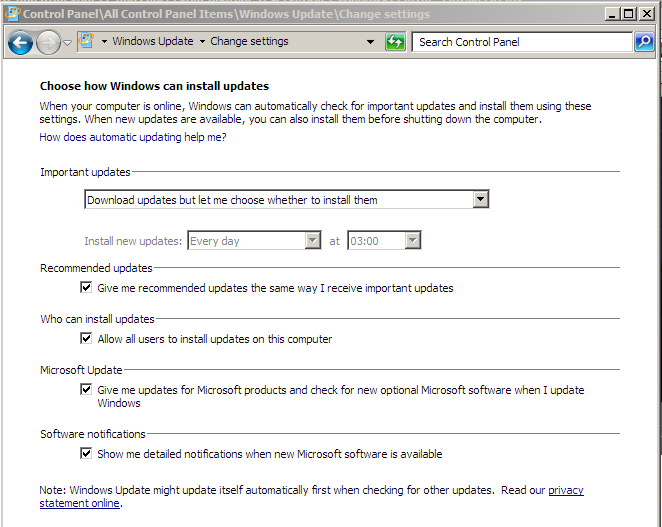
When you get updates, you now have to check each one of them to find out if it is spyware or not. The list above is current as far as I know, but clicking on the “more information” link to the right of the updates list will get you microsoft’s marketing speak obfuscation of the true purpose. Any update that “adds telemetry points” or something like that is spyware. Uncheck the install and hide the update. Note that some of these were moved from “optional” to “important.” Microsoft is absolutely intent on stealing your data and is taking some pretty underhanded steps to make it difficult for you to avoid it.
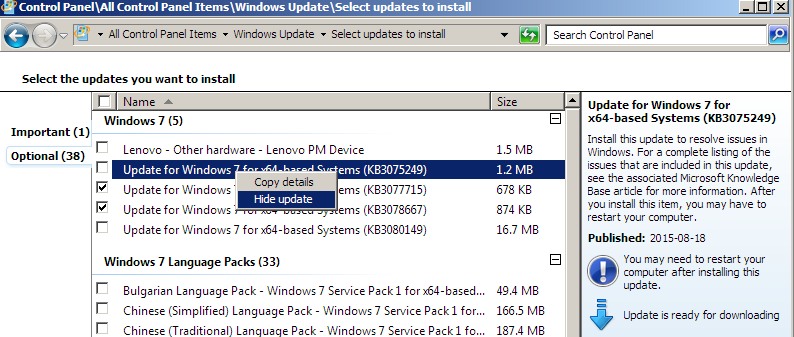
If updates get past you or it turns out later that a seemingly important or innocuous update was spyware (the fun part is that you now have to be vigilant and look all this stuff up), then you can uninstall them from the “installed updates” control panel.
Work to be done
I’ll start looking into firewall settings to block communication to microsoft’s servers. This is a standard anti-malware technique and should work here, except that microsoft has so many servers it is more challenging to block them than your typical malware botnet.
We need something like a variant of Peer Guardian to block microsoft’s servers using the standard P2P crowd-sourcing model to keep the list up to date. I’m not aware of anything like this yet, but I’m looking. Microsoft has become more of an enemy to privacy than the RIAA ever was.
UPDATE: this superuser answer includes a list of telemetry endpoints to block at your firewall or router. Alternatively you can edit your hosts file and add these entries from DSL reports.
Larger Significance
This shift in business focus by Microsoft from providing a product people are willing to pay for to stealing data from people to sell on the commercial market has some significant lessons for the entire software model.
It isn’t just that Microsoft is now adopting Google’s business model of giving away “free” goodies as traps to collect product (you) to sell to the highest bidder, but that the model of corporate trust that underpins most of the security assumptions the internet is built on is manifestly false and unsustainable. If any hacker tried to create these spyware updates, locked-down computers that only install signed code would refuse to install them. Ignoring for the moment that the signed code model is idiotically flawed as signing keys are stolen all the time, this microsoft spyware is properly signed with legitimate keys. It will be installed on locked down computers without complaint and will not show up in commercial anti-virus software. But it is spyware. It contains keyloggers and extremely productive data exfiltration code that is currently copying wholesale data dumps from unfortunate victims to Microsoft’s servers in such volume that their data caps are being hit.
If a non-commercial third party (e.g. “hacker”) did this, they’d be prosecuted. It makes no difference to you that your data is being stolen by Microsoft rather than by some clever teenager in a former eastern block country: your data is being stolen. But the model that has been promoted, a model of centralized corporate trust to validate the “security” of your system has been utterly and irrevocably shattered. This isn’t an accident, isn’t something that better data management might have prevented, this is an intentional ex post facto rewrite of the usual, customary, and regular assumptions we have about the privacy of our computer systems and one that significantly impacts the security of almost everyone in the world: military, medical, legal, fiduciary, as well as personal.
And even if you trust Microsoft (for whatever bizarre, irrational reason), Microsoft is creating a whole series of security holes in their already crappy and insecure operating system that will be exploited by third parties. By adding keyloggers and data exfiltration tools to the core OS, they’re making it even easier for non-corporate hackers to jump on the data theft gravy train. Everyone profits but you. You lose.
Better Cabling May Fix The Internet
Do you find that the internet seems harsh? Do you find Facebook unclear and that it lacks dynamic contrast? Is there less detail than there should be? Do you notice a loss of energy from the Internet?
It might all come down to the network cables themselves.

Well designed cables like these have perfect-surface extreme-purity silver conductors minimizing distortion caused by grain boundaries in inferior OFHC, OCC, or 8N conductors for better clarity and reduced harshness. Explanations and arguments will be both more clearly constructed and less confrontational.
Noise and other distractions are reduced by a 3-layer noise dissipation system, not just shielding your data but preventing modulation of your ground plane by noisy RFI. Even more problematically for those doing research on the web, the untested orientation of standard network cables results in inferior data quality.
Standard network cables either don’t enforce orientation of the pairs at all (Cat 5e and below) or merely segregate pairs with a flexible spacer (Cat 6 and above). These cables use solid polyethylene insulation to ensure critical geometry is preserved to minimize phase errors. Phase errors can easily result in Doppler shifts manifest in either an unnaturally shrill tone or affected bass (sometimes manifest as “mansplaining”).
Most remarkably, the dielectric bias system puts a 72V bias on the insulation and thus organizes the molecules of the insulation to minimize energy loss which creates a surprisingly black background, more essential than ever in the wake of Ferguson.
Only $10,521 for a 12m cable. Now that the internet has become our primary source of information, understanding, and personal communication this is a tiny price to pay for clear, undistorted data.
You Now Have Hemorrhoids
I sign into Facebook and am greeted with the following diagnosis: You how have timeline.
I resisted as long as I could, but sooner or later really bad interface design always seems to poop over everything.
Facebook Lose
For some time now I’ve used Facebook as a broadcast channel for my content. That is, I post to my personal, self-hosted, on my own server, in my own house blog so I actually, unambiguously own my content. Then I let facebook rebroadcast it. That is, apparently, going to end.
They have decided that they will make it more difficult to use facebook to disseminate content facebook doesn’t own – that is any content you actually enter into the facebook interface is facebook’s and they chose whether to keep it or delete it, make money off it or bury it. You’re just an unpaid worker troll feeding their advertising revenue machine, and you will no longer let to play with their toys if you don’t play along.
Social networks are kind of cool, but it will be a good thing when facebook jumps the shark and we get the next iteration. It’ll be a sad day for everyone who has put a lot of effort into gifting facebook with as much content as they can though, when all that UGC goodness ends up on ebay’s used hard disks section for bargain hunters to sift through with disk recovery tools for their own amusement.