author
What’s Right About PGP
Occasionally you find the crankypants commentary about the “problems” with PGP. These commentaries are invariably written by people who fail to recognize the use modality that PGP is meant to address.
PGP is a cryptographic tool that is, genuinely, annoying to use in most current implementations (though I find the APG extension to the K9 mail app on the android as easy or easier to use than the former Enigmail implementation for Thunderbird, since replaced by a less fully featured native implementation.) The purpose of PGP is to encrypt the contents of mail messages sent between correspondents. Characteristics of these messages are that they have more than ephemeral value (you might need to reference them again in the future) and that the correspondents are not attempting to hide the fact that they correspond.
It is intrinsic to the capabilities of the tool that it does not serve to hide with whom you are communicating (there are tools for doing this, but they involve additional complexity) and all messages encrypted with a single key can be decrypted with that key. As such keys are typically protected by a password the user must remember. It is a sufficiently accurate simplification of the process to consider the messages themselves protected by a password that the owner of the messages must remember and might possibly be forced to divulge as the fundamental limit on the security of the messages so protected. There are different tools for different purposes that exchange ephemeral keys that the user doesn’t ever know, aren’t protected by a mnemonic password, and therefore can never be forced to divulge).
These rants against PGP annoy me because PGP is an excellent tool that is marred by minor usability problems. Energy expended on ignorantly dismissing the tool is energy that could be better spent improving it. By far the most important use cases for the vast majority of users that have any real reason to consider cryptography are only addressed by PGP. I make such a claim based on the following:
- Most business and important correspondence is conducted by email and despite the hyperventilation of some ignorant children, will remain so for the foreseeable future.
- Important correspondence, more or less by definition, has a useful shelf life of more than one read and generally serves as a durable (and legally admissible) record.
- There are people who have legitimate reasons to obfuscate their correspondents: email, even PGP encrypted email, is not a suitable tool for this task.
- There are people who have legitimate reason to communicate messages that must not be permanently recorded and for which either the value of the communication is ephemeral or the risk is so great that destroying the archive is a reasonable trade-off: email, even with PGP, is not a suitable tool for this task.
- There’s some noise in the rant about not being sufficient to protect against NSA targeted intercept or thwarting NSA data archiving, which makes an implicit claim that the author has some solution that might provide such protection to end users. I consider such claims tantamount to homicide. If someone is targeted by state-level surveillance, they can’t use a Turing-complete device (any computer device) to communicate information that puts them at risk; any suggestion to the contrary is dangerous misinformation.
Current implementations of PGP have flaws:
- For some reason, mail clients still don’t prompt for the import or generation of PGP keys whenever a new account is set up. That’s somewhat pathetic.
- For some reason, address books integrated into mail clients don’t have a field for the public key of the associate. This is a bizarre omission that necessitates add-on key management plug-ins that just make the process more complicated.
- It is somewhat complicated by IMAP, but no client stores encrypted messages locally in unencrypted form (by default, Thunderbird can do this now), which makes them difficult to search and reduces their value as an archival record. This has trivial security value: your storage device is, of course, encrypted or exposing your email should your device be lost is likely to be the least of your problems.
PGP is, despite these shortcomings, one of the most important cryptographic tools available.
Awesome properties of PGP keys no other cryptographic system can touch
PGP keys are (like all cryptographic keys in use by any system) long strings of seemingly random data. The more seemingly random, the better. They are, by that very nature, nonmnemonic. Public key cryptosystems, like PGP, have an awesome, incredibly useful characteristic that you can publish your public key (a long, random string of numbers) and someone you’ve never met can encrypt a message using that public key and only your private key can decrypt it: a random stranger can initiate crytopgraphically secure communication spontaneously.
Conversely, you can “sign” data with your “private key” and anyone can verify that you signed it by decrypting it with your public key (or more precisely a short mathematical summary of your message). This is so secure, it is a federally accepted signature mechanism.
There’s a hypothesized attack called a Man In The Middle attack (often abbreviated “MITM”) that exploits the fact these keys aren’t really human readable (you can, but they’re so long you won’t) whereby an attacker (traditionally the much maligned Eve) intercepts messages between two parties (traditionally the secretive Alice and Bob), pretending to be Bob whilst communicating with Alice and pretending to be Alice whilst communicating with Bob. By substituting her keys for Alice’s and Bob’s, both Bob and Alice inadvertently send messages that Eve can decrypt and she “simply” forwards Bob’s to Alice using Alice’s public key and vice versa so they decrypt as expected, despite coming from the evil Eve.
Eve must, however, be able to intercept all of Alice and Bob’s communication or her attack may be discovered when the keys change, which is not practical in the real world on an ongoing basis (but, ironically, is easier with ephemeral keys). Pretending to be someone famous is easier and could be more valuable as people you don’t know might send you unsolicited private correspondence intended for the famous person: the cure is widely disseminating key “fingerprints” to make the discovery of false keys very hard to prevent. And if you expect people to blindly send you high-priority information with your public key, you have an obligation to mitigate the risk of a false recipient.
Occasionally it is hypothesized that this attack compromises the utility of PGP; it is a shortcoming of all cryptographic systems that the keys are not human readable if they are even marginally secure. It is intrinsic to a public key infrastructure that the public keys must be exchanged. It is therefore axiomatic that a PKI-based cryptographic system will be predicated on mechanisms to exchange nonmnemonic key information. And hidden key exchange, as implemented by OTR or other ephemeral key systems makes MITM attacks harder to detect.
While it is true that elliptic curve PKI algorithms achieve equivalent security with shorter keys, they are still far too long to be mnemonic. One might nominally equivalence a 4k RSA key with a 0.5k elliptic curve key, a non-trivial factor of 8 reduction with some significance to algorithmic efficiency, but no practical difference in human readability. Migrating to elliptic curves is on the roadmap for PGP (with GPG 2.1, now in beta) and should be expedited.
PGP Key management is a little annoying
Actually, it isn’t so much PGP that makes this true, but rather the fact that mail clients haven’t integrated PGP into the client. That Gmail and Yahoo mail will soon be integrating PGP into their mail clients is a huge step in the right direction even if integrating encryption into a webmail client is kind of pointless since the user is already clearly utterly unconcerned with privacy at all if they’re gifting Google or Yahoo their correspondence. Why people who should know better still use Gmail is a mystery to me. When people who care about data security use a gmail address it is like passing the temperance preacher passed out drunk in the gutter. With every single message sent. Even so, this is a step in the right direction by some good people at Google.
It is tragic that Mozilla has back-burnered Thunderbird, but on the plus side they don’t screw up the interface with pointless changes to justify otherwise irrelevant UX designers as does every idiotic change in Firefox with each release. Hopefully the remaining community will rally around full integration of PGP following the astonishingly ironic lead of the privacy exploiting industry.
If keys were integrated into address books in every client and every corporate LDAP server, it would go a long way toward solving the valid annoyances with PGP key management; however, in my experience key management is never the sticking point, it is either key generation or the hassle of trying to deal with data rendered opaque and nearly useless by residual encryption of the data once it has reached me.
Forward Secrecy has a place. It isn’t email.
A complaint levied against PGP that proves beyond any doubt that the complainant doesn’t understand the use case of PGP is that it doesn’t incorporate forward secrecy. Forward secrecy is a consequence of a cryptosystem that negotiates a new key for each message thread which is not shared with the users and which the system doesn’t store. By doing this, the correspondents cannot be forced to reveal the keys to decrypt the contents of stored or captured messages since they don’t know them. Which also means they can’t access the contents of their stored messages because they’re encrypted with keys they don’t know. You can’t read your own messages. There are messaging modalities where such a “feature” isn’t crippling, but email isn’t one of them; sexting perhaps, but not email.
Indeed, the biggest, most annoying, most discouraging problem with PGP is that clients do not insert the unencrypted message into the local message store after decrypting it. This forces the user to decrypt the message again each time they need to reference it, if they can ever find it again. One of the problems with this is you can’t search encrypted messages without decrypting them. No open source client I’m aware of has faced this debilitating failure of use awareness, though Symantec’s PGP desktop does (so it is solvable). Being naive about message use wouldn’t have been surprising for the first few months of GPG’s general use, but that this failure persists after decades is somewhat shocking and frustrating. It is my belief that the geekiness of most PGP interfaces has so limited use that most people (myself included) aren’t crippled by not being able to find PGP encrypted mail because we get so little of it. If even a small percentage of our mail was encrypted, not ever being able to find it again would be a disaster and we’d stop using encryption.
This is really annoying because messages have the frequently intolerable drawbacks of being ephemeral without the cryptographic value of forward secrecy.
Email is normally used as a messaging modality of record. It is the way in which we exchange contemplative comments and data that exceeds a sentence or so. This capability remains important to almost all collaborative efforts and reducing messaging complexity to chat bubbles cripples cognitive complexity. The record thus created has archival value and is a fundamental requirement in many environments. Maximizing the availability, searchability, and ease of recall of this archive is essential. Indeed, even short form communication (“chat” in various forms), which is typically amenable to forward secrecy because of the generally low content value thus communicated, should have the option of PGP encryption instead of just OTR in order to create a secure but archival communications channel.
A modest proposal
I’ve been using PGP since the mid 1990s. I have a key from early correspondence on PGP from 1997 and mine is from 1998. Yet while I have about 2,967 contacts in my address book I have only 139 keys in my GPG keyring. An adoption rate of 4.7% for encrypted email isn’t exactly a wild success. I don’t think the problems are challenging and while I very much appreciate the emergence of cryptographically secure communications modalities such as OTR for chat and ZRTP for voice, I’ve been waiting for decades for easy-to-use secure email. And yet, when people ask me to help them set up encrypted email, I generally tell them it is complicated, I’m willing to help them out, but they probably won’t end up using it. Over the years, a few relatively easy to fix issues have retarded even my own use:
- The fact that users have to find and install a somewhat complex plugin to handle encryption is daunting to the vast majority of users. Enigmail is complicated enough that it is unusable without in-person walk-through support for most users. Even phone support doesn’t get most people through setup. Basic GPG key generation and management should be built into the mail client. Every time one sets up a new account, you should have to opt out of setting up a public key and there’s no reason for any options by default other than entering a password to protect the private key.
- Key fields should be built into the address book of every mail client by default. Any mail client that doesn’t support a public key field should be shamed and ridiculed. That’s all of them until Gmail releases end-to-end as a default feature, though that may never happen as that breaks Google’s advertising model. Remember, Google pays all their developers and buys them all lunch solely by selling your private data to advertisers. That is their entire business model. They do not consider this “evil,” but you might.
- I have no idea why my received encrypted mail is stored encrypted on my encrypted hard disk along with hundreds of thousands of unencrypted messages and tens of thousands of unencrypted documents. Like any sensible person who takes a digital device out of the house (or leaves it unprotected in the house), I encrypt my local storage to protect those messages and documents from theft and exploitation. My encrypted email messages are merely data cruft I can’t make much use of since I can’t search for them. That’s idiotic and cripples the most important use modality of email: the persistent record. Any mail client should permanently decrypt the local message store unless the user specifically requests a message be stored encrypted, an option that should be the same for a message that arrived encrypted or unencrypted as the client could encrypt mail with the user’s public key on arrival without requiring a password or access to the private key.
- Once we solve the client storage failure and make encrypted email useful for something other than sending attachments (which you can save, ZOMG, in unencrypted form) and feeling clever for having gotten the magic decoder ring to work, then it would make sense to modify mail servers to encrypt all unencrypted incoming mail with the user’s public key, which mitigates a huge risk in having a mail server accessible on the internet: that the historical store of data there contained is remotely compromised. This protects data at rest (data which is often, but not assuredly, already protected in transit by encrypted transport protocols using ephemeral keys with forward security.) End-to-End encryption using shared public keys is still optimal, but leaving the mail store unencrypted at rest is an easily solved at rest security failure while protection in transit is largely solved (and would be quickly if gmail bounced any SMTP connection not protected by TLS 1.2+.)
Fixing the obvious usability flaws in encrypted email are fairly easy. Public key cryptography in the form of PGP/GPG is an incredibly powerful and tremendously useful tool that has been hindered in uptake by limitations of perception and by overly stringent use cases that have created onerous limitations. Adjusting the use model to match requirements would make PGP far more useful and far easier to convince people to use.
Phil Zimmerman’s essay “why I wrote PGP” applies today as much as it did in 1991:
What if everyone believed that law-abiding citizens should use postcards for their mail? If a nonconformist tried to assert his privacy by using an envelope for his mail, it would draw suspicion. Perhaps the authorities would open his mail to see what he’s hiding.
It has been more than 30 years and never has the need for universally encrypted mail been more obvious. It is time to integrate PGP into all mail clients.
Category: FreeBSD • Linux • Technology
Managing (lots of) Digitial Pictures
This is an older method, I do a lot of this with DigiKam now on Linux.
Over the decades, I’ve taken a lot of digital pictures. I was a bit haphazard in backing them up to CDs to random hard disks etc – meaning several copies. Over the years, bit rot has corrupted some copies, CDs from 20 years ago have started to go blank etc. Once I put together a ZFS 6 FreeNAS box, I thought it would be a good place to organize them, especially once I started playing with Picasa’s face recognition tool, which is awesome for reminding me who some of those people are in those old .jpgs staring back through the bit flip block defects of the ages.
I’ve tried a couple of face recognition tools – Microsoft’s, some other thing that really sucked, and Picasa, and Picasa’s is by far the best. Unfortunately Picasa suffers horribly from Google Hubris, that infuriating disease that renders otherwise excellent technologies almost unusable. An example many people have run into is Google’s idiotic threading model in gmail. They’ve decided that all messages are non-hierarchical blobs, that the meta information means nothing, and that we should trust the lucky feeling. If the messages Google chooses to show us aren’t what we were actually looking for, then we are doing it wrong.
Picasa is infected with the same disease, but has it even worse. Picasa has one uniquely good trick, it tags faces fairly well. It is not a particularly good tool, certainly not the best, for many other tasks people do with images. But since failing to recognize that the only right way to do any of these tasks is with Picasa, and really failing to understand that anything anyone would legitimately ever actually want to do with a digital image falls into the set of features Picasa has (or it is not legitimate), the fact that touching your images with any other program corrupts Picasa’s database and, entertainingly, wipes out any work that you’ve done with Picasa is, as reiterated over and over by Google’s reps in the Picasa forums, just proof that you’re doing it wrong.
And, of course, Google and Picasa will be with us forever, just like every image management and editing application that I was using back in 1990 when I started taking digital photos.
My little image collection, once fully deduplicated, is 52,000+ images and 122 GB of data, which I think crosses most predictable size fail thresholds, so if these tools work here, they should be pretty reliable for most people. If you don’t get it yet, and still fail to adhere to the Google Way, the following utilities aided my heresy.
Face Tagging (Fix Picasa with AvPicFaceXmpTagger)
If it wasn’t for the face tagging feature, I’d never use Picasa. I can’t wait until somebody competent writes a face tagging application that is as well written, straight forward, and standards compliant as Friedemann Schmidt’s GeoSetter – a gold standard in image utilities matched only by Irfan Skiljan’s IrfanView. Until then, there is, alas, only Picasa.
With a large collection of images, especially those with crowd shots, one quickly discovers that even Picasa’s devs haven’t through through the UI very well yet: there’s no way to reject large groups of pictures. It is also very tedious to work in manual mode: you can’t add faces in the “identify unknown faces” mode where you’d want to, for example. Another odd artifact is that to move a misidentified collection of faces to the right name, you have to select from a text-only popup list that quickly spans several 1200 pixel screens as you add names. If you type the first letter of the name, it jumps to it, but the scroll wheel doesn’t scroll the list and if you start typing the second letter of the name thinking you’ll get to the one you want (a standard UI reflex) you instead jump around to names beginning with that letter – but bonus feature – if you have only one person in the list who’s name begins with that letter, the reassignment executes automatically, which can make it hard to find where the pictures even went.
If it were me, I’d add an “indicate face” mode where I can indicate with just a click (not click, drag, name each time) where a face is and trigger a “look harder” iteration of the detection algo. It would also be useful to hint to the algo that a folder of images has more faces than already detected, try again. The algo should use meta information to aid in narrowing – for example certain faces tend to appear in different periods of one’s life. A good example might be taking a vacation with a friend: in that folder, everyone who kind of looks like the friend is more likely to be so. That is, look at frequency of appearance by metadata cluster and weight accordingly where metadata might be folder, file naming structure, GeoIP, date, time, etc.
But the huge problem with Picasa is that for reasons that could only make sense to a company that is absolutely, religiously certain they know the one and only true way to do anything correctly, Picasa writes the face ID information to a contacts.xml file, not using standards-compliant XMP face tagging. This means that when your picasa database gets corrupted (and it will, regularly) most of your face tagging efforts are lost if you don’t use a utility to write the face tag data to the EXIF meta information so it stays with the picture.
Fortunately, there is a tool to do just that: Andreas Vogel’s AvPicFaceXmpTagger. This utility will read the contacts.xml file and write the data into the image files as XMP compliant tags so the work will stay with your images. I ran it on my entire pre-deduplicated collection before deduplicating, and while it took about 20 hours, it did not barf.
What is particularly annoying is that the face detection algorithm is actually quite good, it is the database management that is beyond useless. Google has no excuse for being bad at information management. The meta information being attached to a picture couldn’t be easier – a name and coordinates. The contacts.xml file is intolerably fragile and completely tied to Picasa.
GeoTagging (Use GeoSetter)
Picasa used to be my geotag program, but then I found GeoSetter, and I completely abandoned Picasa’s inferior geotagging features and never looked back. It is now just a face recognition tool. It pretty much sucks at managing the data, and while AvPicFaceXmpTagger fixes the inexcusable shortcoming of not writing XMP tags with the face data, as soon as there’s a GeoSetter-quality, XMP-compliant face tagging solution, Picasa is so voted off the hard disk.
GeoSetter uses map integration to make tagging pictures easy, but it does The Right Thing, that is it puts as tags hierarchical place and altitude information as tags. Oddly, Picasa reps argue that geotags don’t do that any more, that is they only put the lat/lon into the picture assuming that the user will always be connected to Google’s servers and look up additional metadata from the lat/long as needed, arrogant, self-centered morons that they are. Real world users that don’t live on the Google campus still interact with their image data when their not connected to the interwebs, as difficult as this would be for Google to understand and as contrary to their plans for world domination as it is.
But Geosetter does it right, so don’t bother geotagging with Picasa. Geosetter will also look up the additional place name metadata based on lat/lon data in the picture and write that to the appropriate EXIF fields. It is powerful, easy to use, and very reliable.
Folder Organization (Organize folders by date with AmoK Exif Sorter)
Organizing pictures is highly subjective and there’s no right way – well except Picasa’s One True Way, but if your read this far, you’re probably not drinking that cool-aide. I, personally, like YYYY/YYYY-MO/YYYY-MO-DY/Image name folder structures. I, personally, don’t end up with more than 3-400 images in any single folder that way (and that very rarely) so OS’s don’t ever barf on a 20,000 image folder and it is fairly easy to find pictures. The tool I use to organize into year/month/day folders is AmoK Exif Sorter, which can read the EXIF create date and move images into my favorite folder structure automatically. It is a little slow on large folders of more than 2-3,000 images, but it didn’t fail on 20,000 images and sorted them all perfectly.
This works well because I use the same image organization with my EyeFi card, which transmits images directly from my camera to my laptop via wifi and sorts them as it goes. Everything prior to getting the card was randomly sorted until Exif Sorter fixed it, but now it should stay in sync. I really like my EyeFi card, but if upload is enabled when I am not in range of a discoverable network, the card sometimes crashes and I lose the last couple of pictures taken. I’m not happy about that, but I usually remember to turn upload off from the camera interface, and it has only made me really sad a few times so far.
DeDuplication (AntiTwin and DupDetector)
If you’re as disorganized as I am then you’ll ultimately end up with quite a few extra copies of your images as the years go by. Some of my collections had more than 10 copies in the nearly two decades since I first took them. I actually use two tools for deduplication: AntiTwin and DupDetector; I tried Picasa’s deduplication tool but it sucks and it isn’t clear that it is actually removing duplicates, rather just faking you into doing work with it that will later be lost when you have to reinstall Picasa in a few days after the database gets corrupted again (see rotation, below).
I do first pass deduplication with AntiTwin and use the byte by byte comparison at 100% match to find bit-for-bit copies. This does not detect copies with different EXIF tags (which happens) or images that are scaled for email and cluttering up your disk along with their original resolution master images, but you can be confident you’re not going to lose anything. I directly delete the copies AntiTwin finds. AntiTwin also has an image compare function, but it is useless on a large image collection.
To find scaled copies, copies with exif info, copies with minor bit rot, etc that AntiTwin won’t find, I use Prismatic Software’s DupDetector. I’ve found an odd mix of versions on download sites, and the author site is very slow, but it isn’t too huge and it works very well and has been recently updated. I use it to move, not delete copies, into a dead storage folder. If I make a mistake, the copies are still there, but I don’t need to have them in my primary search path. I am fairly confident that everything detected as a duplicate with match at 99.9% was actually a duplicate, but at 99.7%, it turned up some icon sized scaled pictures along with a lot of false matches in very dark pictures. I suggest first running at 100% in fully automatic mode, then cautiously at 99.9% in fully automatic mode; I only had 420 detected duplicates at 99.7%, and about half of those were true duplicates, so I ran at 99.7% in semi-auto mode.
Rotation (IrfanView)
One of the last steps for me is orienting all of my pictures upright using a JPEG Lossless rotation. In yet another facepalm move, Picasa fakes you out with rotations – it does not actually rotate the image, it just stores your rotation specification in picasa.ini file in the folder, which only Picasa uses, and that’s only until that file gets hosed for some reason. So if you spent a couple of days scrolling through the giant list of all your images rotating them one by one in Picasa, you wasted your time. Sorry. Thank Google.
Fire up IrfanView, load a directory of images, or even all subdirectories, and you can autorotate a giant library according to EXIF information. If your pictures go back more than about 5 years, your camera probably didn’t have an orientation sensor, so auto-rotate wont work. But Irfan’s thumbnail mode lets you select a few thousand images that need to be rotated the same way on by one (but quickly) and batch rotate them all losslessly.
If you do this, Picasa will still apply the picasa.ini rotation you created and it will be wrong, which is a good reminder not to use Picasa for anything any other program does better.
Category: photo • Positive • Reviews • Technology
Pro-IP Act sucks.
Slashdot reported (others too, I’m sure) that the Pro-IP act has passed the Judiciary Committee. This is yet another evil copyright expansion that blatantly contradicts the plain English meaning of the 8th clause of Section 8 of the First Article:
“To promote the Progress of Science and useful Arts, by securing for limited Times to Authors and Inventors the exclusive Right to their respective Writings and Discoveries”
This particular bill authorizes seizure of property in copyright cases – a mechanism that has resulted in gross abuse in drug cases and is repugnant to the rule of law.
The /. article linked to William Patry’s blog, who is now one of my heroes. His blog discusses an article by Neil Natenel: “Why Has Copyright Expanded? Analysis and Critique.” It is an excellent discourse on the prevailing contortions exploited to provide legal cover for industry-drafted legislation that has so distorted the concepts of copyright and hobbled the advancement of technology and science.
Natenel’s counterarguments against ideas as property and neoclassical market optimization were convincing but I think missed something, though there is a full-length book on the same subject I have yet to read.
(My thoughts below but they reference the article.)
Category: Politics
Ovulatory cycle effects on tip earnings by lap dancers
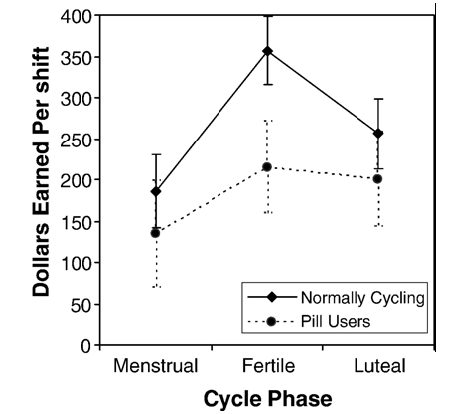
In an article titled “Ovulatory cycle effects on tip earnings by lap dancers: economic evidence for human estrus?” in the Journal of Evolution and Human Behavior 28 (2007) 375-381, Geoffrey Miller, Joshua M. Tybur, & Brent D. Jordan presented the results of an experiment designed to test the correlation of tips earned by lap dancers as a function of fertility as a proxy for sexual desirability.
The study was soundly constructed and enrolled 18 dancers who supplied data on 296 work shifts and approximately 5300 lap dance performed during that period. A lap dance was described as “entail[ing] intense rhythmic contact between the female pelvis and the clothed male penis.” (Barton, 2006; Beasley, 2003).
The results showed that exotic dancers in heat earned approximately $70 per hour, dancers in luteal phase earned about $50 per hour, while dancers “on the rag” earned about $35 per hour. Taking the pill, which induces a state of pseudo-pregnancy, results in an income loss of about 30%, which suggests substantially diminished sexual desirability; a good reason to consider an IUD.
The author’s conclude that:
"In serially monogamous species such as ours, women's estrous signals may have evolved an extra degree of plausible deniability and tactical flexibility to maximize women's ability to attract high-quality extra-pair partners just before ovulation, while minimizing the primary partner's mate guarding and sexual jealousy. For these reasons, we suspect that human estrous cues are likely to be very flexible and stealthy—subtle behavioral signals that fly below the radar of conscious intention or perception, adaptively hugging the cost–benefit contour of opportunistic infidelity."
Perhaps the most interesting revelation of the paper is the number of academic research papers that have been published on exotic dancers including, in addition to this one:
Mulberry Mail is Excellent

Not too long ago I got on a plane with Thunderbird, having transitioned to IMAP, woke my laptop in flight and found my imap mail cache had gotten borked. Five useful work hours wasted. So in my searches for “Thunderbird Disconnected Problems” I found mention of this program called “Mulberry” that didn’t have these problems. I had looked at Mulberry years ago and it was cool, but fee and Eudora was then current and free so I didn’t try it out. I am so glad I found it again. Mulberry handles disconnected IMAP perfectly, has a fast powerful search, and is well-organized. I’ve had no problems and I’m using it to write this now on an 11 hour flight.
At the outset, it is clear this is the vision of a single programmer not the work of committee and as such it is quirky and has some unique solutions. I wouldn’t say it is more quirky than Eudora but at first one will definitely spend time searching for functions and consulting the somewhat thin documentation. The basics are easy enough, but some advanced features are non-obvious.
Further, Mulberry is Correct. That is it is a fairly precise implementation of just about every mail standard, including some that are still emerging. Not surprising as the author, Cyrus Daboo, has also written some of the key server-side programs that run the web, including some of the really hard bits like the SASL authentication engine I use on my server and one of the most popular IMAP servers. If something doesn’t connect it is because the other program (the server or whatnot) is making a mistake. This is great as far as it goes, but some non-RFC compliant usages have become commonplace and sticking to the RFC can cause problems. An example I found quickly was that the Message-ID: header Mulberry generates is constructed as unique-message-string@[client.dotted.quad] (something like 3499345954.0253243@[192.168.15.101]). This is correct, but the standard is to use @my.smtpserver.com, and using a non-fully qualified extension (the dotted quad, not a valid domain name). The dotted quad looks spammy to spam filters, and in particular when the client is on NATed DHCP, the private IP (192.168.etc) it looks bad. So Mulberry sourced mail might get a slightly higher SpamAssassin score (it is not a fatal test, but it can’t help) and my procmail spam filter looks for disagreement as a test so I can’t email myself notes to my own account – I have to send them to my MIT account.
Cyrus says he is going to fix this.
Which brings me to another wonderful feature of Mulberry: it has great support from the mailing list and author. You won’t go more than 24 hours without an answer to the most technical questions. And as it is in active development, any bugs are going to be fixed. Compare this to a MS product where that is not going to happen.
Mulberry’s mail interface took me a little getting used to. For example the mailbox list is organized a little differently and single clicks open new mailboxes in the next pane and the message in the pane below it, but this behavior can all be customized in the Window->Options… menu including, critically for me: do not mark previewed message as read.
Another good trick is automatically moving read messages out of the inbox. I haven’t been entirely satisfied with the sort options: the unread messages always seem to sort in the reverse order of what I want, putting the messages I need at the interface between the read and unread messages, rather than at the top or bottom. But the auto move mechanism works well for my inbox and lets me sort the inbox by date, it being all unread mail, the read mail automatically being moved to an archive.
I spent some time figuring out two wonderful features: Mulberry (along with GCalDaemon) supports off-line calendar sync with Google Calendar (YAY! I can answer email about my calendar while I’m on a plane and even schedule a meeting!) and I can sync to ScheduleWorld’s LDAP server (which syncs to my phone address book and my work Outlook address book). And since I use ScheduleWorld to sync my work Outlook calendar to Google calendar, I’ve got all my important information at hand, even in the air. I wrote up the steps to make these tricks work on the Mulberry Wiki.
Even the search function is fast – entirely tolerable though perhaps not quite real-time like Google Desktop, but then again you don’t need to open inane stupid brain dead IE to perform the search like Google Desktop forces you to.
Mulberry is great. It works really well, it is stable, it works offline (disconnected), it syncs right, it has a very good offline calendar client, IMAP support seems flawless, it has great keyboard shortcuts, and fast advanced search. It does everything I need and it is now free, open source, and available for Windows, Linux, and Mac OSX.
Category: Positive • Reviews • Technology
-
Recent Posts
- Goodbye, Tortuga. 2024 April 25
- A one page home/new tab page with random pictures, time, and weather 2024 April 11
- Putting ccache on a backed RAM disk to speed compiles 2024 March 16
- Audio File Analysis With Sox 2024 February 07
- Manually Update Time Zone Data on Android 10 2023 October 31
- Autodictating to self using Whisper to preserve privacy 2023 August 17
- Projecting Qubit Realizations to the Cryptopocalpyse Date 2023 August 04
- AI PSYOPS are changing strategic messaging 2023 July 29
- Convert A Slideshow/Presentation into HTML 5 Video 2023 July 23
- Mobotix Notifier in Python – get desktop messages from your cameras 2023 June 06
- Categories
- Links
- Search
- Archives
- Post History
It looks like Internet radio is going away. That’s sad because it was a good application of streaming IP media and a nice innovation. It’s also sad because it demonstrates once again how divorced copyright law is from the constitutional clause that justifies it:
To promote the progress of science and useful arts, by securing for limited times to authors and inventors the exclusive right to their respective writings and discoveries
Copyright is not a property right; copyright is an agreement between the public and authors & inventors creating a privilege of limited exclusive right as incentive for dissemination of ideas because otherwise authors & inventors have only the choice of keeping their inventions secret or sharing them that the recipient does what he or she will with the information without limitation, which is the natural right of the recipient.
Any mechanism of securing exclusive right to the author or inventor must meet two tests to be constitutional:
An attempt was made to test the absurdly long exclusive term against the “limited” requirement and that failed because any finite term is by definition limited.
The test that must now be made is against the requirement that copyright laws “promote the progress of science and the useful arts.” The burden of proof should be on demonstrating that the laws do promote the progress of science and the useful arts because copyright is a limitation on the rights of the public and therefore intrinsically a burden on society. In granting copyright society temporarily yields their natural right to a privilege offered authors & inventors, a privilege that may be revoked at any time.
Current copyright laws do not pass the test of promoting the progress of science and the useful arts; they are a burden on innovation and have systematically retarded the progress of science and technology, strangling many significant innovations, once again with internet radio. Current copyright laws are therefore unconstitutional.
And seriously retarded.