WebP and SVG
Using WebP coded images inside SVG containers works. I haven’t found any automatic way to do it, but it is easy enough manually and results in very efficiently coded images that work well on the internets. The manual process is to Base64 encode the WebP image and then open the .svg file in a text editor and replace the
xlink:href="data:image/png;base64, ..."
with
xlink:href="data:image/webp;base64,..."
(“…” means the appropriate data, obviously).
Back in about 2010 Google released the spec for WebP, an image compression format that provides a roughly 2-4x coding efficiency over the venerable JPEG (vintage 1974), derived from the VP8 CODEC they bought from ON2. VP8 is a contemporary of and technical equivalent to H.264 and was developed during a rush of innovation to replace the aging MPEG-II standard that included Theora and Dirac. Both VP8 and H.264 CODECs are encumbered by patents, but Google granted an irrevocable license to all patents, making it “open,” while H.264s patents compel licensing from MPEG-LA. One would think this would tend to make VP8 (and the WEBM container) a global standard, but Apple refused to give Google the win and there’s still no native support in Apple products.
A small aside on video and still coding techniques.
All modern “lossy” (throwing some data away like .mp3, as opposed to “lossless” meaning the original can be reconstructed exactly, as in .flac) CODECs are founded on either Discrete Cosine Transform (DCT) or Wavelet (DWT) encoding of “blocks” of image data. There are far more detailed write ups online that explain the process in detail, but the basic concept is to divide an image into small tiles of data then apply a mathematical function that converts that data into a form which sorts the information from least human-perceptible to most human-perceptible and sets some threshold for throwing away the least important data while leaving the bits that are most important to human perception.
Wavelets are promising, but never really took off, as in JPEG2000 and Dirac (which was developed by the BBC). It is a fairly safe bet that any video or still image you see is DCT coded thanks to Nasir Ahmed, T. Natarajan and K. R. Rao. The differences between 1993’s MPEG-1 and 2013’s H.265 are largely around how the data that is perceptually important is encoded in each still (intra-frame coding) and some very important innovations in inter-frame coding that aren’t relevant to still images.
It is the application of these clever intra-frame perceptual data compression techniques that is most relevant to the coding efficiency difference between JPEG and WebP.
Back to the good stuff…
Way back in 2010 Google experimented with the VP8 intra-coding techniques to develop WebP, a still image CODEC that had to have two core features:
- better coding efficiency than JPEG,
- ability to handle transparency like .png or .tiff.
This could be the one standard image coding technique to rule them all – from icons to gigapixel images, all the necessary features and many times better coding efficiency than the rest. Who wouldn’t love that?
Apple.
Of course it was Apple. Can’t let Google have the win. But, finally, with Safari 14 (June 22, 2020 – a decade late!) iOS users can finally see WebP images and websites don’t need crazy auto-detect 1974 tech substitution tricks. Good job Apple!
It may not be a coincidence that Apple has just released their own still image format based on the intra-frame coding magic of H.265, .heif and maybe they thought it might be a good idea to suddenly pretend to be an open player rather than a walled-garden-screw-you lest iOS insta-users wall themselves off from the 90% of the world that isn’t willing to pay double to pose with a fashionable icon in their hands. Not surprisingly, .heic, based on H.265 developments is meaningfully more efficient than WebP based on VP8/H.264 era techniques, but as it took WebP 10 years to become a usable web standard, I wouldn’t count on .heic having universal support soon.
Oh well. In the mean time, VP8 gave way to VP9 then to VP10, which has now AV1, arguably a generation ahead of HEVC/H.265. There’s no hardware decode (yet, as of end of 2020) but all the big players are behind it, so I expect 2021 devices will and GPU decode will come in 2021. By then, expect VVC (H.266) to be replacing HEVC (H.265) with a ~35% coding efficiency improvement.
Along with AV1’s intra/inter-frame coding advance, the intra-frame techniques are useful for a still format called AVIF, basically AVIF is to AV1 (“VP11”) what WEBP is to VP8 and HEIF is to HEVC. So far (Dec 2020) only Chrome and Opera support AVIF images.
Then, of course, there’s JPEG XL on the way. For now, the most broadly supported post-JPEG image codec is WEBP.
SVG support in browsers is a much older thing – Apple embraced it early (SVG was not developed by Google so….) and basically everything but IE has full support (IE… the tool you use to download a real browser). So if we have SVG and WebP, why not both together?
Oddly I can’t find support for this in any of the tools I use, but as noted at the open, it is pretty easy. The workflow I use is to:
- generate a graphic in GIMP or Photoshop or whatever and save as .png or .jpg as appropriate to the image content with little compression (high image quality)
- Combine that with graphics in Inkscape.
- If the graphics include type, convert the type to SVG paths to avoid font availability problems or having to download a font file before rendering the text or having it render randomly.
- Save the file (as .svg, the native format of Inkscape)
- Convert the image file to WebP with a reasonable tool like Nomacs or Ifranview.
- Base64 encode the image file, either with base64
# base64 infile.webp > outfile.webp.b64or with this convenient site - If you use the command line option the prefix to the data is “
data:image/webp;base64,“ - Replace the … on the appropriate
xlink:href="...."with the new data using a text editor like Atom (RIP). - Drop the file on a browser page to see if it works.
WordPress blocks .svg uploads without a plugin, so you need one
The picture is 101.9kB and tolerates zoom quite well. (give it a try, click and zoom on the image).

Integrate Fail2Ban with pfSense
Fail2Ban is a very nice little log monitoring tool that is used to detect cracking attempts on servers and to extract the malicious IPs and—do the things to them—usually temporarily adding the IP address of the source of badness to the server’s firewall “drop” list so that IP’s bad packets are lost in the aether. This is great, but it’d be cool to, instead of running a firewall on every server each locally detecting and blocking malicious actors, to instead detect across all services and servers on the LAN and push the results up to a central firewall so the bad IPs can’t reach the network at all. This is one method to achieve that goal.
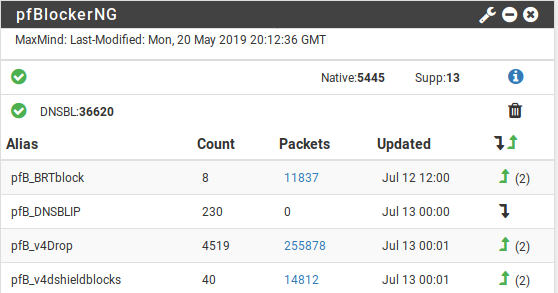
NOTE: pfBlockerNG v3.2.0_3 adding a “_v4” suffix to the auto-generated IPv4 aliases. The shell script that runs on pfSense to update the alias via pfctl should be modified to match.
I like pfSense as a firewall and run FreeBSD on my servers; I couldn’t find a prebuilt tool to integrate F2B with pfSense, but it wasn’t hard to hack something together so it worked. Basically I have F2B maintain a local “block list” of bad IPs as a simple text file which is published via Apache from where pfSense’s grabs it and applies it as a LAN-wide IP filter. I use the pfSense package pfBlockerNG to set up the tables but in the end a custom script running on the pfSense server actually grabs the file and updates the pfSense block lists from it on a 1 minute cron job.
There are plenty of well-written guides for getting F2B working and how to configure it for jails; I found the following useful:
- https://www.digitalocean.com/community/tutorials/how-fail2ban-works-to-protect-services-on-a-linux-server
- https://dan.langille.org/2015/05/10/wordpress-and-fail2ban/
- https://forums.freebsd.org/threads/fail2ban-with-jails.49150/
- https://protectli.com/kb/how-to-setup-pfblockerng/
- https://synaptica.info/en/2019/06/09/pfsense-cron-iterface/
Note that this how-to assumes you have or can get F2B working and that you’ve got pfSense working and know how to install packages (like pfBlockerNG). I did not find sufficient detail in any one of the above sources to make setting it up a copy-pasta experience, but in aggregate it worked out.
The basic model is:
- Internet miscreants try to hack your site leaving clues in the log files
- Fail2Ban combs the log files to determine which IPs are are associated with sufficiently bad (and sufficiently frequent) behavior, which is normally used to update the host’s local firewall block list, adding and removing miscreant IPs according to rules defined in
.localjail scripts. - Instead of updating the firewall’s
iptableslist, a custombanactionscript (see below) instead writes the IPs to a list that is published to the LAN by a web server (or to the world, if you want to share). - pfSense, running on a different server, is configured to pull that list of miscreant IPs into pfBlockerNG as a standard IPv4 (in my case, IPv6 is also possible) block list.
- To get around pfBlockerNG’s too slow maximum update rate of 1 hour, a bash script runs on an every minute cron job on the pfSense server to
curlthe list over and update pfSense’spfctl(packet filter control) directly, which to some extent bypasses fail2ban other than letting it maintain the aliases and stats. - Packets from would be evildoers evaporate at the firewall.
This model is federatable – that is sites can make their lists accessible either via authenticated (e.g. client cert or scp) or open sharing of dynamic lists. This might be a nice thing as some IP block lists have gone offline or become subscription only. Hourly (or less frequent) updates would require only subscribing to someone’s HTTP/FTP published F2B dynamic miscreant list in pfBlockerNG or by adding bash/cron jobs to update more frequently.
I do not publish my list because it would seem to provide a bit of extra information to an attacker, but if someone with a specific IP that can be allowed wants it, I’m happy to except that IP.
The custom bits I did to get it to work with pfSense are:
Custom F2B Action
On the protected side, I modified the “dummy.conf” script to maintain a list of bad IPs as a banaction in an Apache served location that pfSense could reach. F2B manages that list, putting bad IPs in “jail” and letting them out as in any normal F2B installation—but instead of using the local server’s packet filter as the banaction, they’re pushed to a web-published text list. This list contains any IP that F2B has jailed, whether in the SSH jail or the Apache jail or the Postfix jail or whatnot based on banactions per jail.local config. Note that until the pfSense part of the process is set up, F2B is only generating a web-published list of miscreants trying to hack your system.
# Fail2Ban configuration file
#
# Author: David Gessel
# Based on: dummy.conf by Cyril Jaquier
#
[Definition]
# Option: actionstart
# Notes.: command executed on demand at the first ban (or at the start of Fail2Ban if actionstart_on_demand is set to false).
# Values: CMD
#
actionstart = if [ -z '<target>' ]; then
touch <target>
printf %%b "# <init>\n" <to_target>
fi
chmod 755 <target>
echo "%(debug)s started"
# Option: actionflush
# Notes.: command executed once to flush (clear) all IPS, by shutdown (resp. by stop of the jail or this action)
# Values: CMD
#
actionflush = if [ ! -z '<target>' ]; then
rm -f <target>
touch <target>
printf %%b "# <init>\n" <to_target>
fi
chmod 755 <target>
echo "%(debug)s clear all"
# Option: actionstop
# Notes.: command executed at the stop of jail (or at the end of Fail2Ban)
# Values: CMD
#
actionstop = if [ ! -z '<target>' ]; then
rm -f <target>
touch <target>
printf %%b "# <init>\n" <to_target>
fi
chmod 755 <target>
echo "%(debug)s stopped"
# Option: actioncheck
# Notes.: command executed once before each actionban command
# Values: CMD
#
actioncheck =
# Option: actionban
# Notes.: command executed when banning an IP. Take care that the
# command is executed with Fail2Ban user rights.
# Tags: See jail.conf(5) man page
# Values: CMD
#
actionban = printf %%b "<ip>\n" <to_target>
sed -i '' '/^$/d' <target>
sort -u -n -t . -k 1,1 -k 2,2 -k 3,3 -k 4,4 <target> -o <target>
chmod 755 <target>
echo "%(debug)s banned <ip> (family: <family>)"
# Option: actionunban
# Notes.: command executed when unbanning an IP. Take care that the
# command is executed with Fail2Ban user rights.
# Tags: See jail.conf(5) man page
# Values: CMD
#
# flush the IP using grep which is supposed to be about 15x faster than sed
# grep -v "pattern" filename > filename2; mv filename2 filename
actionunban = grep -v "<ip>" <target> > <temp>
mv <temp> <target>
chmod 755 <target>
echo "%(debug)s unbanned <ip> (family: <family>)"
debug = [<name>] <actname> <target> --
[Init]
init = BRT-DNSBL
target = /usr/jails/claudel/usr/local/www/data-dist/brt/dnsbl/brtdnsbl.txt
temp = <target>.tmp
to_target = >> <target>
The target has to be set for your web served environment (this would be FreeBSD default host root). I’ve configured mine to be visible on the LAN only via .htaccess in the webserverroot/dnsbl/ directory.
AuthType Basic Order deny,allow Deny from all allow from 127.0.0.1/8 10
Then you need to call this as a banaction for the infractions that will get miscreants blocked at pfSense, for example in ./jail.local you might modify the default ban action to be:
# Default banning action (e.g. iptables, iptables-new, # iptables-multiport, shorewall, etc) It is used to define # action_* variables. Can be overridden globally or per # section within jail.local file banaction = brtdnsbl #banaction_allports = iptables-allports
or say in ./jail.d/sshd.local you might set
[sshd] enabled = true filter = sshd banaction = brtdnsbl maxretry = 2 findtime = 2d bantime = 30m bantime.increment = true bantime.factor = 2 bantime.maxtime = 10w logpath = /var/log/auth.log
But do remember to set your ignoreip as appropriate to prevent locking yourself out by having your own IP end up on the bad guy list. You can make a multi-line ignoreip block like so:
ignoreip = 127.0.0.1/8 ::1 10.0.0.0/8 12.114.97.224/27 15.24.60.0/23 22.31.214.140 13.31.114.141 75.106.28.144 125.136.28.0/23 195.170.192.0/19 72.91.136.167 24.43.220.14 18.198.235.171 17.217.65.19
That is put a leading space on continuation lines following the ignoreip directive. This isn’t documented AFAIK, so it might break, but works as of fail2ban version 0.11.2_3
Once this list is working (check by browsing to your list):
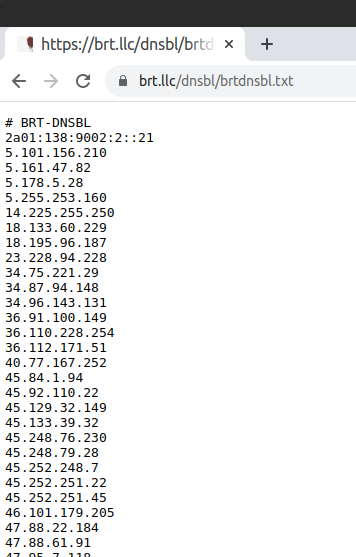
then move to the pfSense side to actually block these would be evildoers and scriptkiddies.
Set up pfBlockerNG
The basic setup of pfBlockerNG is well described, for example in https://protectli.com/kb/how-to-setup-pfblockerng/ and it provides a lot of useful blocking options, particularly with externally maintained lists of internationally recognized bad actors. There are two basic functions, related but different:
DNSBL
Domain Name Service Block Lists are lists of domains associated with unwanted activity and blocking them at the DNS server level (via Unbound) makes it hard for application level services to reach them. A great use of DNSBLs is to block all of Microsoft’s telemetry sites, which makes it much harder for Microsoft to steal all your files and data (which they do by default on every “free” Windows 10 install, including actually copying your personal files to their servers without telling you! Seriously. That’s pretty much the definition of spyware.)
It also works for non-corporate-sponsored spyware, for example lists of command and control servers found for botnets or ransomware servers. This can help prevent such attacks by denying trojans and viruses access to their instruction servers. It can also easily help identify infected computers on the LAN as any blocked requests are sent to what was supposed to be a null address and logged (to 1.1.1.1 at the moment, which is an unfortunate choice given that is now a well-reputed DNS server like Google’s 8.8.8.8 but, it seems, without all the corporate spying.) There is a bit of irony in blocking lists of telemetry gathering IPs using lists that are built using telemetry.
Basically DNSBLs prevent services on the LAN from reaching nasty destinations on the internet by returning any DNS request to look up a malicious domain name with a dead-end IP address. When your windows machine wants to report your web browsing habits to microsoft, it instead gets a “page not found” error.
IPBL: what this process uses to block baddies
This integration concept uses an IPBL, a list of IP addresses to block. An IPBL works at a lower level than a DNSBL and typically is set up to block traffic in both directions—a script kiddie trying to brute force a password can be blocked from reaching the target services on the LAN, but so too can the reverse direction be blocked—if a malicious entity trips F2B, not only are they blocked from trying to reach in, so too are any sneaky services on your LAN blocked from reaching out to them on the internet.
All we need to do is get the block list F2B is maintaining into pfSense. pfBlockerNG can subscribe to the list URL you set above easily enough just like any other IPv4 block list but the minimum update time is an hour.
My IPv4 Settings for the Fail2Ban list look like this:
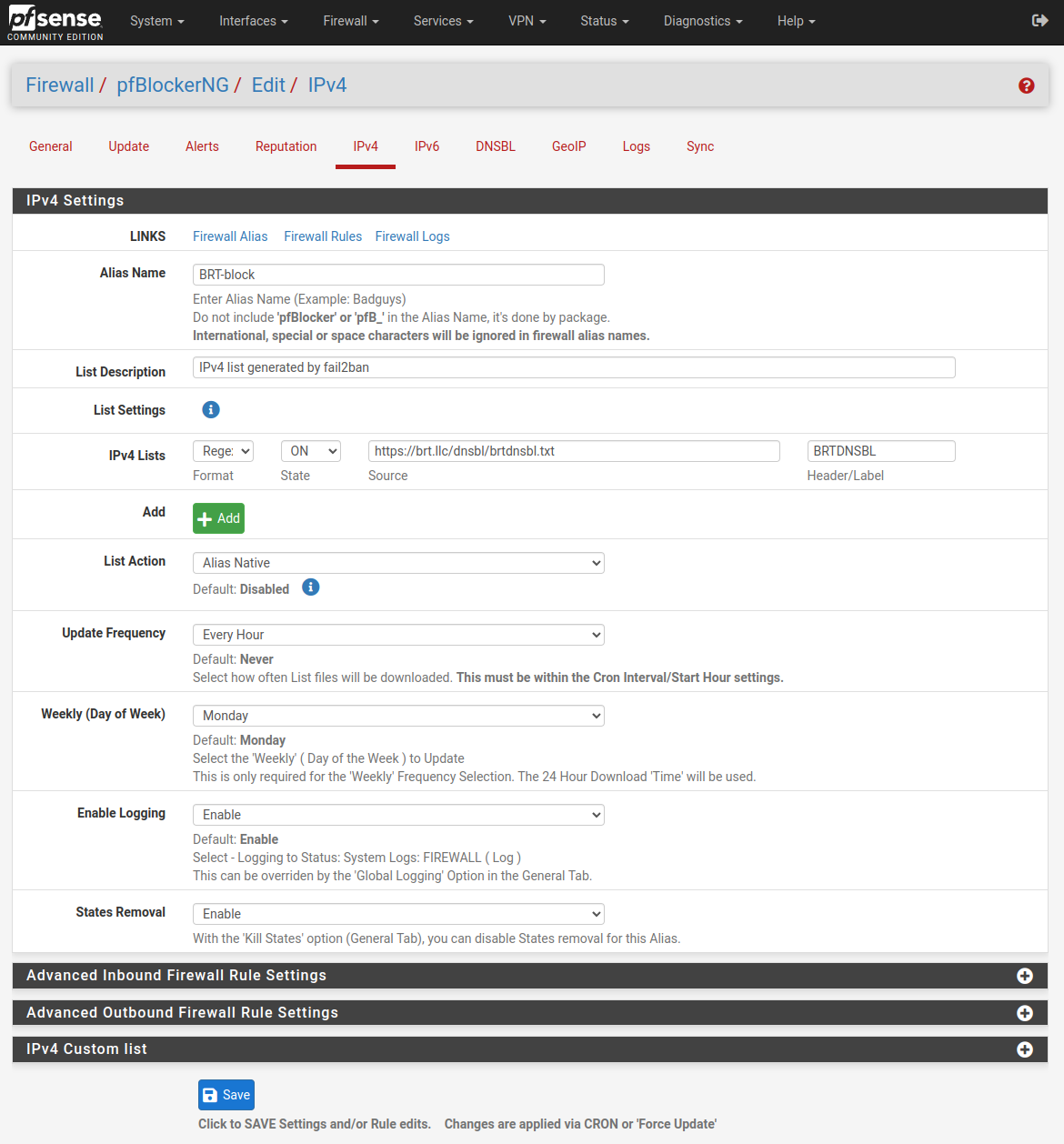
An hour is an awfully long time to let someone try to guess passwords or flood your servers with 404 requests or whatever else you’re using F2B to detect and stop. So I wrote a simple script that lives on the pfSense server in the/root/custom directory (which isn’t flushed on update) and that executes a few simple commands to grab the IP list F2B maintains, do a fairly trivial grep to exclude any non-IP entries, and use it to update the packet filter drop lists via pfctl:
/root/custom/brtblock.sh
#!/usr/bin/env sh
# set -x # uncomment for "debug"
# Get latest block list
/usr/local/bin/curl -m 15 -s https://brt.llc/dnsbl/brtdnsbl.txt > /var/db/pfblockerng/original/BRTDNSBL.orig
# filter for at least semi-valid IPs.
/usr/bin/grep -Eo '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' /var/db/pfblockerng/original/BRTDNSBL.orig > /var/db/pfblockerng/native/BRTDNSBL.txt
# update pf tables
# for pfBlockerNG ≤ v3.2.0_3, omit the _v4 suffix shown below
/sbin/pfctl -t pfB_BRTblock_v4 -T replace -f /var/db/pfblockerng/native/BRTDNSBL.txt > /dev/null 2>&1
HT to Jared Davenport for helping to debug the weird /env issues that arise when trying to call these commands directly from cron with the explicit env declaration in the shebang. Uncommenting the set -x directive will generate a verbose output for debugging. Getting this script onto your server requires ssh access or console access. If you’re adventurous it can be entered from the Diagnostics→Command Prompt tool.
Preventing Self-Lockouts at pfSense
One of the behaviors of pfBlockerNG that the dev seems to think is a feature is automatic filter order management. This overrides manually set filter orders and will put pfB’s block filters ahead of all other filters, including, say, allow filters of your own IPs that you don’t want to ever be locked out in case you forget your passwords and accidentally trigger F2B on yourself. This will override your own reordering. If this default behavior doesn’t work for you, then use a non-default setting for IPv4 block lists and make all IP block list “action” types “Alias_Native.”
To use Alias_Native lists, you write your own per-pfBlockerNG alias filter (typically “drop” or “reject”) and then pfBlockerNG won’t auto-order them for you on update. We let pfBlockerNG maintain the alias list at something like pfB_BRTblock (the pfB_ prefix is added by pfBlockerNG) which we then use like any other alias in manual firewall rule:
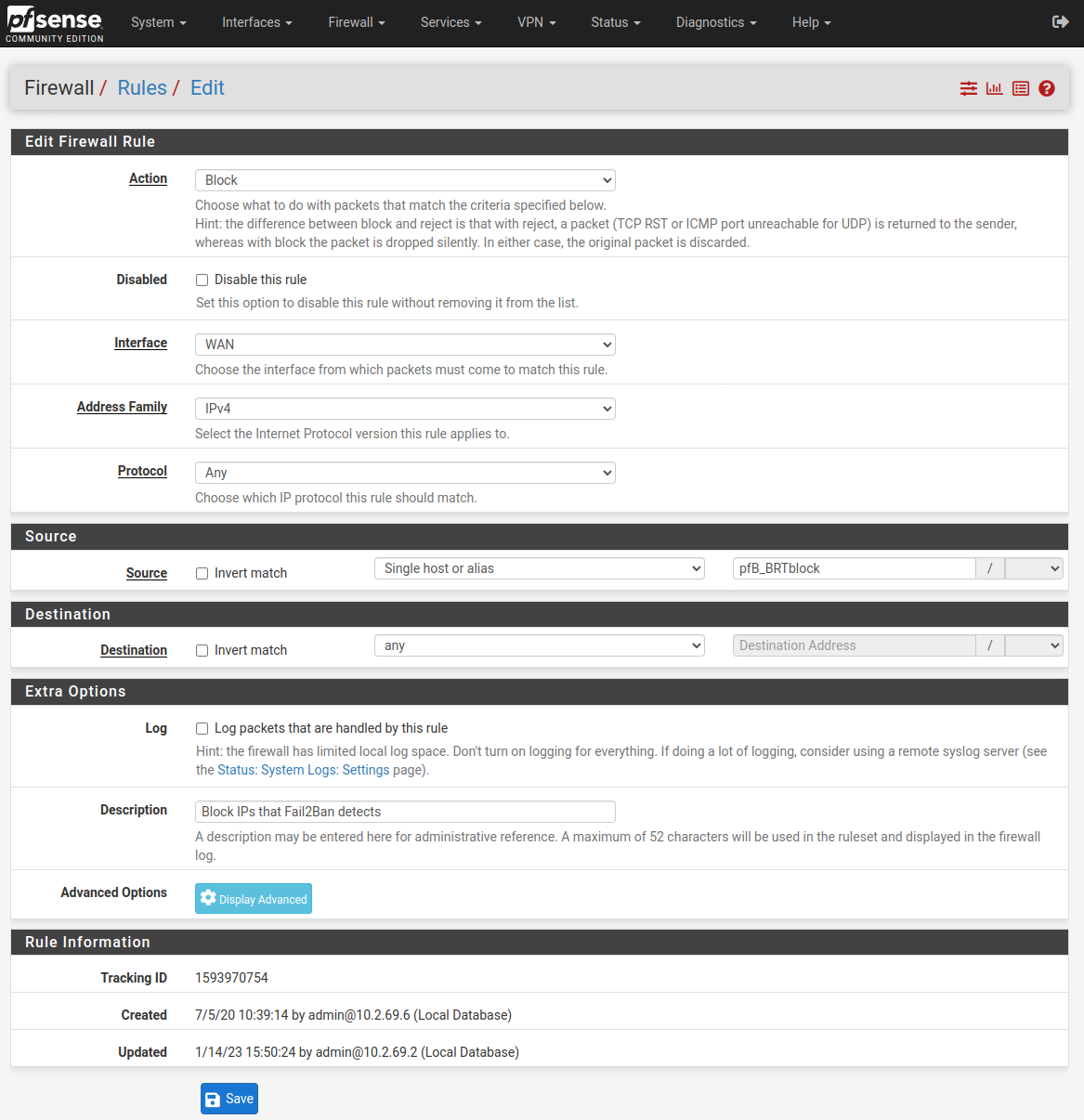
So the list of rules looks like this:
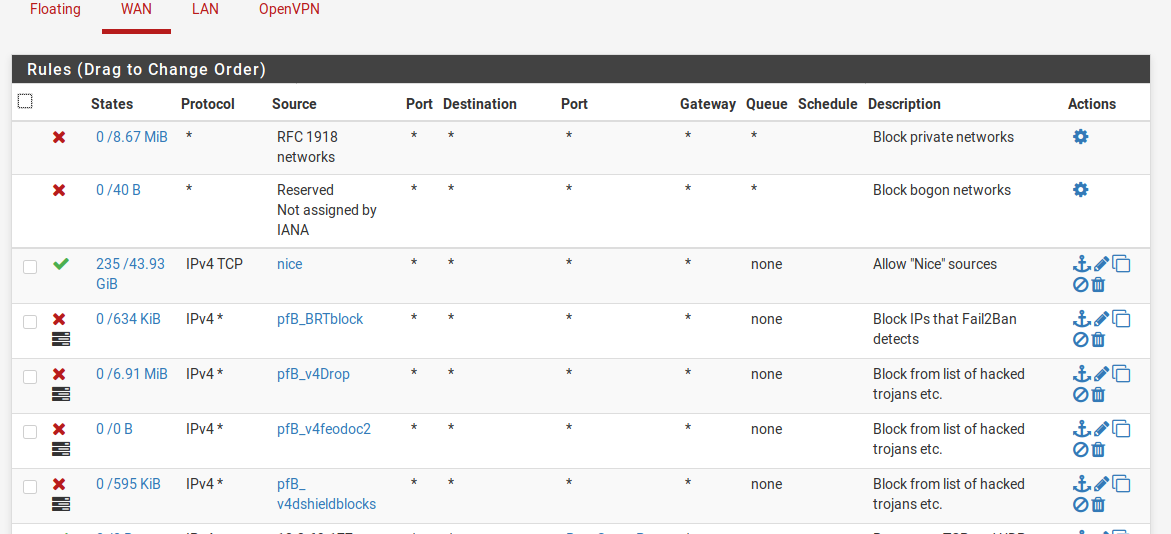
Cron Plugin
The last ingredient is to update the list on pfSense quickly. pfSense is designed to be pretty easy to maintain so it overwrites most of the file structure on upgrade, making command line modifications frustratingly transient. I understand that /root isn’t flushed on an upgrade so the above script should persist inside the /root directory. But crontab -e modifications just don’t stick around. To have cron modifications persist, install the “Cron” package with the pfSense package manager. Then just set up a cron job to run the script above to keep the block list updated. */1 means run the script once a minute.
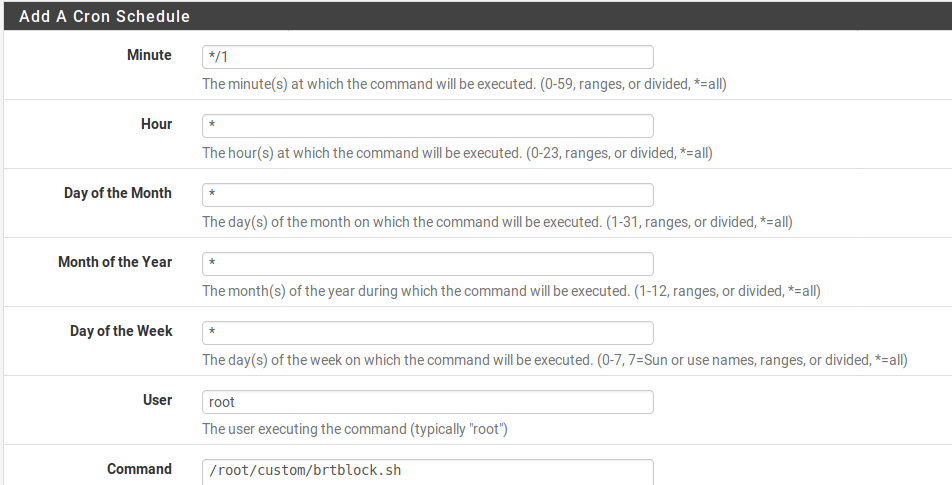
Results
The system seems to be working well enough; the list of miscreants as small, but effectively targeted: 11,840 packets dropped from an average of about 8-10 bad IPs at any given time.
A few C19 Predictions (from 2020-05-05)
UPDATE: Sept 2022
The introduction of the first successful vaccine was much faster than I anticipated, the first shots going into arms Dec 14, 2020, just 7 months after I wrote this – a lot shorter than the 18 months generally predicted in early 2020. This was due to the emergency use authorization given to the mRNA vaccines which were already much further along than I was aware based on a decade’s research on SARS. That was great and unexpected news. Otherwise things have generally played out as predicted from relatively short immunity (we should all be getting our 5th shot around now) and almost certainly contributing to the global instability we’re experiencing globally.
The most reasonable way to plan for the future is to project from the past. Anything else is magical thinking.
There’s no vaccine, there’s no rational reason to believe one will be generally available in <18 months even if any of the current candidates works perfectly, there’s plenty of reasons to believe there will not be one in our lifetimes, by far the most likely outcome based on the lack of success of all vaccine efforts to date for corona family viruses, which have included many promising candidates that made it into human trials only to prove ineffectual. Sure, maybe we get lucky, but so too we might all win the lottery. The history of corona virus vaccine development projects forward to no vaccine for a long, long time if ever. Anyone confidently saying “when a vaccine is available” rather than “if a vaccine is available” is thinking magically. “When we figure out warp drive, we can visit the stars!” Further, if immunity isn’t long lasting, so too will vaccines be short-lived, not that getting a shot every 3 years or even every 3 months isn’t vastly better than getting sick with a potentially fatal disease that often. It is, and even a short-lived vaccine will at least make life much easier for those with access to it.
| Immunity/Vaccine | No Vaccine | Vaccine works |
| Short Immunity | Average human lifespan drops substantially, wealthy countries benefit from pharmaceutical interventions, travel never recovers. | Wealthy populations live normally but with regular boosters, poor die young(er) |
| Long Immunity | Poor/uncontrolled populations have economic advantage due to rapid herd immunity. | Starting 18 months after successful P3 trials, 1-2 years to wealthy country immunity. In 40-50 years C19 may be completely eradicated. |
This means that, while the possibility of a vaccine as a path to immunity without getting sick is possible, it isn’t probable. It is not rational to isolate with the expectation of escaping a C19 infection, rather isolation delays the (probably) inevitable infection almost everyone is going to get, isolation should be considered a purely temporary strategic pause that is squandered if not used to best advantage.
There’s no novel or specific pharmaceutical intervention, though some medications show promise of mitigating mortality. It does appear that good old-fashioned high-quality medical care in not overwhelmed facilities achieves an amazing reduction in CFR – from 12-14% all the way down to about 0.6% and possibly even lower. Sure, that’s probably at least a big chunk of sampling bias, but not all and that’s pretty awesome. It is normal that treatment improves with sufficient attention and resources and also quite reasonable to expect that some combination of medications will help mitigate the impact of the disease, perhaps systemically (for everyone who gets it), but almost certainly for mitigating certain problematic conditions. Some improvement is inevitable given the wide range of outcomes as good data accumulates: there are reasons why there is so much difference in outcome, we will figure some of those out. Science: it takes time, but it is happening.
This means is that delaying getting sick by quarantine or other measures has two values – first and most importantly it reduces the risk of overloading regional medical response capabilities which seems to, and reasonably would, correlate with much better patient outcomes. It also means it isn’t absurd to delay as long as possible getting sick if you fall into one of the categories currently indicated as being particularly at risk for a bad outcome as it isn’t unreasonable to believe the protocols for achieving a successful outcome will improve in time, even absent a miracle drug.
All solutions are hyped, none are promising: by now people have to be getting jaded reading breathless headlines or absurdly emphatic pre-pub papers about this team or that discovering some cure or being on the verge of a vaccine. Every researcher is working late hoping to be the hero that saves humanity, and we’re all desperate to find that hero, but so far, there’s no easy solution. We’re all inclined to fall into a confirmation bias trap finding some iconoclastic researcher claiming promising results from a process that confirms one’s own pet theory: that should always be a red flag. This is a long slog: years, perhaps many.
Humanity has to prepared to live with this from now on, even while hoping for a vaccine or cure. It isn’t something we can hide inside from until it gets bored and goes away. It isn’t some planet-to-planet salesman who’s going to give up if we don’t come to the door and move on. As a species, we have to find some enduring accommodation to a disease that is highly contagious, is transmissible in individuals with no symptoms, and has a problematically high mortality rate. We are not sure yet whether we will develop lasting immunity and push it into containable corners of the population eventually or not, but even the least controlled areas will take many months if not years to develop R<1.0 herd immunity necessary to ensure a single infectious person doesn’t trigger an exponentiation surge in the sick and dying, and they will do so at high cost. The regions that practice the most effective interventions delay achieving herd immunity, possibly indefinitely if immunity isn’t long lasting.
Universal quarantine is not sustainable: stay at home orders are intrinsically temporary, whether the people issuing them understand this or not. How long they will last depends on submission level of the population, “herd economics” – that is the economic capacity of a sufficient majority to maintain law and order, and the interventions of the government or community to mitigate the consequences. “Economic” consequences are just an abstraction of hunger, homelessness, access to medical care, funeral services, heat, air conditioning, light, and refrigeration; the poorest regions are falling first to the economic (and medical) consequences of quarantine: in Kenya more people have been executed for violating quarantine than have died of C19. There are riots in India and Lebanon, massive protests in the US. This can not last, it is an emergency temporary hold to buy time to design and implement a sustainable mitigation or it is an astonishingly tragic waste of the limited resources humanity had in the face of a calamity that will merely delay the inevitable and result in a far, far worse systemic outcome than doing nothing would have. If quarantine collapses without a clear plan, it does so at the exhaustion of capital resources, both individual and governmental, and drops a globally impoverished world, still lacking sufficient immunity, into a now globally distributed pandemic that we still have almost no resistance to and have far less resources to fight.
Lifting quarantine just because the “curve has flattened” is extremely dangerous. All universal quarantine does is brute-force stop transmission. It doesn’t magically make people more immune. It doesn’t magically make the disease vanish from the planet. Universal quarantine obviously will be effective in stopping transmission, which will, obviously, lower infection rates and death rates, and just as obviously ending quarantine will simply dump a still susceptible population into a, once again, high transmission environment and, of course, case rates and death rates will rise. Quarantine can be safely relaxed when other effective mitigation strategies are in place and working. Optimally, a staged series of incremental relaxations, each expected to raise transmission rates by some manageable amount offsetting a reduction achieved by a more economically viable intervention should be phased in while monitoring the results. Any step that pushes transmission rates beyond what can be managed should be rescinded until additional effective mitigation protocols are in place.
It isn’t hopeless – management is possible, even absent a miracle like UVC suppositories or bleach injections. One might think of the problem this way:
A) You have some density of infectious people,
B) You have some density of susceptible people,
C) You have some rate of transmission between the infectious and the susceptible,
D) you have some rate of death due to the infection.
The combination of A, B, and C is the Rate of Transmission, R₀. As long as this is above 1.0, the infection grows. There’s some level of “D” that we’re willing to tolerate where R₀ doesn’t matter. In most countries, D seems to increase with R, from a nearly tolerable level to a level that we’re not willing to tolerate. Therefore the goal is simply to intervene to control R₀ so that D is as acceptable as it can reasonably be. Not so tricky. But we have to keep in mind that some solutions are sustainable and tolerable and some are not. We could just execute everyone with a fever. We could just lock everyone into their homes and execute anyone who steps outside. We could also just burn down the homes of any infected person with the family inside (a la Milan c 1350). While any of these would be quite effective and, if instituted globally would eradicate the virus; some solutions might not be acceptable in all regions.
We know for sure now that universal quarantine, even without martial law, does control R₀ quite well by only managing C, but only for so long before it falls apart and becomes unacceptable. We also know for sure now that even one infectious person (A) interacting with an unprotected population (B), under “normal” interaction conditions (C) results in catastrophic values for D. It is not rational to believe A will ever be zero.
So we need to find something other than universal quarantine, something that is sustainable that reduces A, B, and/or C such that R₀ is low enough that D is acceptable. B will decline naturally as the percentage of the surviving population is “recovered,” and will do so fastest in those regions with the highest rates of infection, therefore, the level of control, C, necessary to keep D in check will decrease over time even without an advances in treatment. Further, there isn’t only one solution to C: there are many ways to achieve lower transmission rates; we need to find those that match regional infection rates to regional medical capacity at the lowest economic cost.
While there may be a perfect solution to any one of ABCD someday, that’s highly unlikely. But it isn’t needed if there are sufficient yet acceptable partial solutions to all that work together to get D where we can live with it:
A) Accessible testing, contact tracing, wide-area temperature screening, serum testing, etc. all help to reduce A, the density of the infectious. None of these have to be perfect, all any has to do is selectively preferentially identify the infected out of the uninfected and include a mechanism for isolating them and it helps reduce A, the effective density of the infectious—it might not be a “solution” in and of itself, but it doesn’t have to be. Detection only works if there’s a tolerable mechanism for isolating the infected from the interaction pool but this really shouldn’t be hard or economically untenable given we isolated everyone and most people have neither starved nor died unnecessary at home from conditions normally treatable. The better targeted and the more constrained (in breadth and time) the isolation, the lower the economic impact, but of course at a cost. Balancing the cost of isolation interventions with efficacy is dynamic..
B) Identification of those particularly likely to suffer adverse outcomes and isolating them specifically rather than everyone should, it seems from data so far, be a possible way to reduce D substantially in a selective and therefore more sustainable way. This means gathering more data on co-morbidity, screening, and providing targeted isolation and support for those at risk. As above: everyone is isolated now and it hasn’t collapsed the world yet; selective isolation of the susceptible is less effective but more sustainable. Most importantly, the more people who get sick and recover the lower the ratio of susceptible people will be; this is the only reliable end game. As time goes on, it is reasonable to believe the ratio of recovered will rise and become the most significant “intervention” in reducing transmission.
C) So far as I’ve seen (and WHO reports) the only mode of statistically meaningful transmission is droplets and direct contact, neither airborne nor delayed contact shows up in transmission analysis. While there may be indirect transmission by fomites or airborne transmission occasionally, the rate is so low as to be lost in the noise of the data available. This suggests that relatively sustainable mechanisms will be able to effectively mitigate C, such as universal outgoing breath filtering masks on the potentially infected population (meaning simple masks that capture droplet spray for just about everybody for now), input filtering masks on the most vulnerable susceptible population (meaning N95 grade masks to block ingestion of viral particles), wide spread hand washing and sterilization protocols, and other interventions as transmission routes are validated.
D) In time, research on infection rates will improve understanding of disease progression and validate effective interventions to mitigate it. The better this works, the lower the cost of allowing people to get sick and the more rapidly we can allow people to transition from susceptible to recovered.
It will take some carefully controlled epidemiological work and a lot of involuntary human experimentation to find a combination of factors that simultaneously optimize C19 mortality rates and economic viability, but that is just science and does not rely on any miracles. It will, for sure, be less than full lock down. It will not, for sure, be “back to normal”—at least not until 70% or so of the population has recovered—and that’s assuming at least long-term immunity, which may not happen. If long-term immunity isn’t conferred by recovery, a balanced combination of interventions is sustainable indefinitely, though obviously not ideal.
Lock down is already ending intentionally and catastrophically. In the US this is without any rational follow on plan, just “oh well, lets see what happens.” This is not a mystery… recovered rates are about 1-4% or so by now, which is utterly insufficient for herd immunity to meaningful reduce “B” and justify ending meaningful control of “C.” Places that “go back to normal” will be disasters in 3-5 weeks. That will, alas, set back more rational plans to relax universal quarantine, which are needed and must happen to minimize the consequences of an economic catastrophe. Germany is, intelligently, focusing on Re and health care load. They got Re to 0.7, started relaxing, and now it is back up to 1.0. At Re 1.1, Merkel estimates health care fails in Oct and at Re 1.3 in June. A rise in Re with the relaxation of isolating interventions is expected—the research we need is to provide an understanding of which interventions have the highest benefit:cost ratio.
Perhaps by late summer or early fall people will start realizing this is a long term problem and we have to find a way to live with it and various sustainable mitigation combinations might be tried and those that are successful understood and those that are not abandoned. Until then, the world is fumbling blindly.
I suspect that within a year there will be a “new normal” that permits some travel (at least with carte jaune for the recovered) and fairly normal commerce. I expect unemployment rates to peak around 40%, widespread global food insecurity, weaker governments will topple and there will be regional wars intensifying, which is already happening, and new wars emerging. Intrinsically social businesses will remain or return to being outlawed in those areas were law still holds force (I am pretty confident the entire US will be relatively stable as will most developed countries). This means no (sit down) restaurants, bars, clubs, movies, etc. Population mortality rates in stable areas will be around 1% of total population but in regions without sufficient stability it will be 10%+. Regions that “fail” will be problematic sources of unrest, terrorism, and reservoirs of disease for many, many years to come as even the recent marginally effectual international interventions will be far less economically viable for the countries that have historically provided aid.
Herd immunity will become meaningful in about a year in unstable regions with about 5%-10% loss of total population. In stable regions, herd immunity might reach 30-40% in this time, sufficient for meaningful improvements in social constraints. Unemployment will begin to decline after it peaks in about year, though there will be intermediate rises as falls as intervention mechanisms are tested and some fail; I anticipate in this time stable regions will move into optimistic territory and start rebuilding, though it will be a long process.
I’d think that within 3-5 years there will be sufficient global herd immunity that in combination with mass screening protocols that will be “normal” by then and with protective protocols for the most vulnerable, most people will interact socially and economically more or less as we remember we used to. I doubt total population reduction will be much more than 2-5%, mostly driven by the poor who were made homeless/resource-less due to economic dislocation; the wealthy will get through with 0.5-1.0% total loss. I’d think by this time we’d have a post-plague restructuring of the economy mostly complete. Flattening curves are very encouraging in most of the world, but those areas are locked down with universal quarantine; flattening curves are what should happen under such restrictions, but no underlying conditions have changed from when infection rates were rocketing up exponentially other than lockdown itself so if lockdown ends infection rates will also rebound.
The US may have to default though that depends on global outcomes. I am dubious of the US’s ability to weather this well. While economics isn’t a zero sum game, neither is it unbounded. It is largely relative and the US is incurring massive debt under the assumption that it will be manageable because of the US’s historical economic position. This depends on a market for US debt which depends on US economic capability relative to the rest of the world. Asia was gaining fast on US economic hegemony and there has been ongoing pressure, exacerbated by the unpopular actions of the administration, to find an alternative to the USD as the reserve currency. If this happens, US debt could collapse quite suddenly as the cost of equity-securitized debt creates a potentially catastrophic negative feedback loop that can unpredictably result in runaway inflation. On the other hand, everyone hates China right now and come November the US might have less problematic leadership. Should the US be the source of vaccine or effective medical intervention, the US could emerge as we did from WWII: as the provider of economic and military expertise to the successful regions of the world, even if this seems optimistic at the moment.
Save your email! Avoid the Thunderbird 68 update
UPDATE: 78 just repeated history with another unwelcome surprise update.
I’ve come to some peace with 68 as most of the really critical plugins were updated. But 78 is a long way from there and TB devs have continued to create some really bad blood with add-on developers. I’d argue that the strategy being taken by the devs toward compatibility is defensible, but they seem deaf to the empty wasteland they’ve made of the add-on marketplace. For me, one of the critical deficiencies is losing the support of the Enigmail developers (curiously, this 2019 post seems to be a bit behind release 2.2.4.1, which apparently adds support (!).)
A key issue is that many add-ons require hooks into the base code to be able to do things like add menus or interact with users and most of these were terminated. There is a mechanism by which tentative experimental access to many (but not all) of the previously available hooks can still be connected, but taking advantage of that experimental access still imposes a burden of rewriting, refactoring, and retesting – and then recovering user trust. All for a provisional access status that the TB devs helpful advise developers they should beg and plead to make core lest it be capriciously disabled at any future update. Understandably, those devs who stuck with TB through several major revisions of the add-on architecture and suffered reputational and time cost because of them, perceive this “convince us you’re worthy and we may grant a permanent reprieve to your code should we consider it not utterly beneath our notice” attitude as off putting.
(This is now a bit obsolete, referencing the last screw-ya’ll update that was pushed out without notice or option, it is clearly too much to hope that TB devs stop being so sure that “if you don’t do email our way, you’re doing it wrong.”)
TL:DR
If you’ve customized TB with plugins you care about, DO NOT UPDATE to 68 until you verify that every plugin you use is compatible. TB will NOT check for you and once you launch 68, the plugins that have been updated to 68 compatibility will not work with 60.x, which means you better have a backup of your .thunderbird profile folder or you’re going to be filled with seething rage and you’ll have to undo the update. This misery is the consequence of Mozilla having failed to fully uphold their obligation to the user and developer communities that rely on and have enhanced the tools they control.
BTW: if you’re using Firefox and miss the plugins that made it more than just a crappy clone of Chrome, Waterfox is great and actually respects users and community developers. Give it a try.
Avoid Thunderbird 68 Hell
To avoid this problem now and in the future, you have to disable automatic updates. In Thunderbird: Edit->Preferences->Advanced->General-[Config Editor…]->app.update.auto=False, app.update.enabled=False.
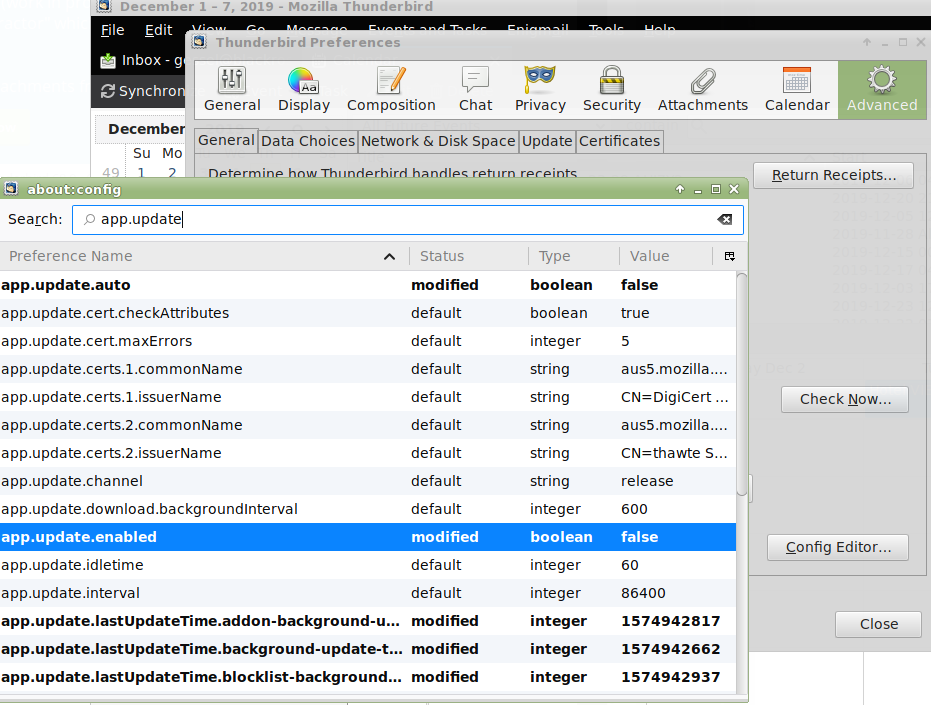
On Linux, you should also disable OS Updates using Synaptic: select installed thunderbird 60.x and then from the menu bar Package->Lock Version.
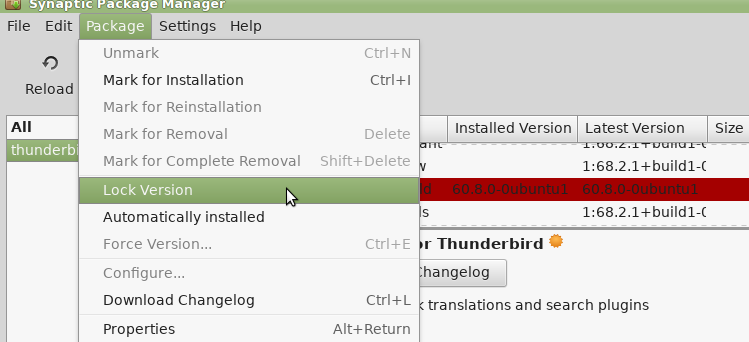
If you’ve been surprise updated to the catastrophically incompatible developer vanity project and massive middle finger to the plugin developer community which is 68 (and 60 to a lesser extent), then you have to revert. This sucks as 60.x isn’t in the repos.
Undo Thunderbird 68 Hell
First, do not run 68. Ever. Don’t. It will cause absolute chaos with your plugins. First it showed most incompatible, then updated some, then showed others compatible, but had deleted the .xpi files so they weren’t in the .thunderbird folder any more, despite being listed and shown incorrectly as compatible. This broke some things I could live without like Extra Format Buttons, but others I really needed like Dorando Keyconfig and Sieve. Mozilla’s attitude appears to be “if you’re using software differently than we think you should, you’re doing it wrong.”
The first step before breaking things even more is to backup your .thunderbird directory. You can find the location from Help->Troubleshooting Information->Application Basics->Profile Directory. Just click [Open Directory]. Make a backup copy of this directory before doing anything else if you don’t already have one, in linux a command might be:
tar -jcvf thunderbird_profile_backup.tar.bz2 .thunderbird
If you’re running Windows, old installers of TB are available here.
In Linux, using a terminal, see what versions are available in your distro:
apt-cache show thunderbird
I see only 1:68.2.1+build1-0ubuntu0.18.04.1 and 1:52.7.0+build1-0ubuntu1. Oh well, neither is what I want. While in the terminal uninstall Thunderbird 68
sudo apt-get remove thunderbird
As my distro, Mint 19.2, only has 68.x and 52.x in the apt cache, I searched to find a .deb file of a recent version. I couldn’t find the last plugin compatible version, 60.9.0 as an easy to install .deb (though it is available for manual install from Ubuntu) so I am running 60.8.0, which works. One could download the executable file of 60.9.1 .and put it somewhere (/opt, say) and then update start scripts to execute that location.
I found the .deb file of 60.8.0 at this helpful historical repository of Mozilla installers. Generally the GUI will auto-install on execution of the download. But don’t launch it until you restore your pre-68 .thunderbird profile directory or it will autocreate profile files that are a huge annoyance. If you don’t have a pre-68 profile, you will probably have to hunt down pre-68 compatible versions of all of your plugins, though I didn’t note any catastrophic profile incompatibilities (YMMV).
Good luck. Mozilla just stole a day of your life.
Frequency of occurrence analysis in LibreOffice
One fairly common analytic technique is finding out, for example, the rate at which something appears in a time referenced file, for example a log file.
Lets say you’re looking for the rate of some reported failure to determine, say, whether a modification or update had made it better or worse. There are log analysis tools to do this (like Splunk), but one way to do it is with a spreadsheet.
Assuming you have a table with time in a column (say A) and some event text in another (say B) like:
11-19 16:51:03 a bad error happened 11-19 16:51:01 something minor happened 11-19 12:51:01 cat ran by
you might convert that event text to a numerical value (into, say, column C) for example by:
=IF(ISERROR(FIND("error",B1)),"",1)
FIND returns true if the text (“error”) is found, but returns an error if not. ISERROR inverts that and returns logical values for both. The IF ISERROR construction allows one to specify values if the text is found or not – a bit complex but the result in this case will be “” (blank) if “error” isn’t found in B1 and 1 if “error” is found.
Great, fill down and you have a new column C with blank or 1 depending if “error” was found in column B. Summing column C yields the total number of lines in which the substring “error” occurred.
But now we might want to make a histogram with a sum count of the occurrences within a specific time period, say “errors/hour”.
Create a new column, say column D, and fill the first two rows with date/time values separated by the sampling period (say an hour), for example:
11/19/2019 17:00:00 11/19/2019 16:00:00
And fill down; there’s a quirk where LibreOffice occasionally loses one second, which looks bad. It probably won’t meaningfully change the results, but just edit the first error, then continue filling down.
To sum within the sample period use COUNTIFS in (say) column E to count the occurrences in entire columns that meet a string of criterion: in this case three criterion have to be met: the value of C is 1 (not “”), The value of A (time) is before the start of the sampling period (D1) and after the end (D2). That is:
=COUNTIFS(C1:C500,"1",$A1:$A500,">="&$D2,$A1:$A500,"<"&$D1)
Filling this formula down populates the sampling periods with the count per sampling period, effectively the occurrence rate per period, in our example errors/hour.
Lets encrypt with security/dehydrated (acme-client is dead)
Well…. security/acme-client is dead. That’s sad.
Long live dehydrated, which uses the same basic authentication method and is pretty much a drop in replacement (unlike scripts which use DNS authentication, say).
In figuring out the transition, I relied on the following guides:
- https://ogris.de/howtos/freebsd-dehydrated.html
- https://wiki.freebsd.org/BernardSpil/LetsEncrypt.sh
- https://erdgeist.org/posts/2017/just-add-water.html
If you’re migrating from acme-client, you can delete it (if you haven’t already)
portmaster -e acme-client
And on to installation. This guide is for libressl/apache24/bash/dehydrated. It assumes you’ve been using acme-client and set it up more or less like this.
Installation of what’s needed
if you don’t have bash installed, you will. You can also build with ZSH but set the config before installing.
cd /usr/ports/security/dehydrated && make install clean && rehash
or
portmaster security/dehydrated
This guide also uses sudo, if it isn’t installed:
cd /usr/ports/security/sudo && make install clean && rehash
or
portmaster /security/sudo
Set up directories and accounts
mkdir -p /var/dehydrated pw groupadd -n _letsencrypt -g 443 pw useradd -n _letsencrypt -u 443 -g 443 -d /var/dehydrated -w no -s /nonexistent chown -R _letsencrypt /var/dehydrated
If migrating from acme-client this should be done but:
mkdir -p -m 775 /usr/local/www/.well-known/acme-challenge chgrp _letsencrypt /usr/local/www/.well-known/acme-challenge
# If migrating from acme-client
chmod 775 /usr/local/www/.well-known/acme-challenge chown -R _letsencrypt /usr/local/www/.well-known
Configure Dehydrated
ee /usr/local/etc/dehydrated/config
add/adjust
014 DEHYDRATED_USER=_letsencrypt 017 DEHYDRATED_GROUP=_letsencrypt 044 BASEDIR=/var/dehydrated 056 WELLKNOWN="/usr/local/www/.well-known/acme-challenge" 065 OPENSSL="/usr/local/bin/openssl" 098 CONTACT_EMAIL=gessel@blackrosetech.com
save and it should run:
su -m _letsencrypt -c 'dehydrated -v'
You should get roughly the following output:
# INFO: Using main config file /usr/local/etc/dehydrated/config Dehydrated by Lukas Schauer https://dehydrated.io Dehydrated version: 0.6.2 GIT-Revision: unknown OS: FreeBSD 11.2-RELEASE-p6 Used software: bash: 5.0.7(0)-release curl: curl 7.65.1 awk, sed, mktemp: FreeBSD base system versions grep: grep (GNU grep) 2.5.1-FreeBSD diff: diff (GNU diffutils) 2.8.7 openssl: LibreSSL 2.9.2
File adjustments and scripts
by default it will read /var/dehydrated/domains.txt for the list of domains to renew
Migrating from acme-client? Reuse your domains.txt, the format is the same.
mv /usr/local/etc/acme/domains.txt /var/dehydrated/domains.txt
Create the deploy script:
ee /usr/local/etc/dehydrated/deploy.sh
The following seems to be sufficient
#!/bin/sh /usr/local/sbin/apachectl graceful
and make executable
chmod +x /usr/local/etc/dehydrated/deploy.sh
Give the script a try:
/usr/local/etc/dehydrated/deploy.sh
This will test your apache config and that the script is properly set up.
There’s a bit of a pain in the butt in as much as the directory structure for the certs changed. My previous guide would put certs at /usr/local/etc/ssl/acme/domain.com/cert.pem, this puts them at /var/dehydrated/certs/domain.com
Check the format of your certificate references and use/adjust as needed. This worked for me – note you can set your key locations to be the same in the config file, but the private key directory structure does change between acme-client and dehydrated.
sed -i '' "s|/usr/local/etc/ssl/acme/|/var/dehydrated/certs/|" /usr/local/etc/apache24/extra/httpd-vhosts.conf
Or if using httpd-ssl.conf
sed -i '' "s|/usr/local/etc/ssl/acme/|/var/dehydrated/certs/|" /usr/local/etc/apache24/extra/httpd-ssl.conf
And privkey moves from /usr/local/etc/ssl/acme/private/domain.com/privkey.pem to /var/dehydrated/certs/domain.com/privkey.pem so….
sed -i '' "s|/var/dehydrated/certs/private/|/var/dehydrated/certs/|" /usr/local/etc/apache24/extra/httpd-vhosts.conf
# or
sed -i '' "s|/var/dehydrated/certs/private/|/var/dehydrated/certs/|" /usr/local/etc/apache24/extra/httpd-ssl.conf
Git sum certs
su -m _letsencrypt -c 'dehydrated --register --accept-terms'
Then get some certs
su -m _letsencrypt -c 'dehydrated -c'
-c is “chron” mode which is how it will be called by periodic.
and “deploy”
/usr/local/etc/dehydrated/deploy.sh
If you get any errors here, track them down.
Verify your new certs are working
cd /var/dehydrated/certs/domain.com/ openssl x509 -noout -in fullchain.pem -fingerprint -sha256
Load the page in the browser of your choice and view the certificate, which should show the SHA 256 fingerprint matching what you got above. YAY.
Automate Updates
ee /etc/periodic.conf
insert the following
weekly_dehydrated_enable="YES" weekly_dehydrated_user="_letsencrypt" weekly_dehydrated_deployscript="/usr/local/etc/dehydrated/deploy.sh" weekly_dehydrated_flags="-g"
note the flag is –keep-going (-g) Keep going after encountering an error while creating/renewing multiple certificates in cron mode
Update Waterfox with the new PPA on Mint 19.1
The Waterfox PPA changed recently. The following let me update from 56.2.8 to 56.2.10 (between which the old PPA was removed).
First remove the old hawkeye PPA from your sources list, then:
echo "deb http://download.opensuse.org/repositories/home:/hawkeye116477:/waterfox/xUbuntu_18.04/ /" | sudo tee -a /etc/apt/sources.list wget -nv https://download.opensuse.org/repositories/home:/hawkeye116477:/waterfox/xUbuntu_18.04/Release.key -O Release.key sudo apt-key add - < Release.key sudo apt update sudo apt upgrade
Note Ubuntu 18.04 = Mint 19/19.1 the 18.10 deb fails.
1976 GMC Suburban
When I was a young child, my dad bought a brand new 1976 GMC Suburban. Yellow. No extras at all – no head liner, plastic seats, manual everything, 305 V8.
It became my car in high school, survived that. Came out to California with me; ended up in the service of SRL, survived that too.
Eventually, it escaped.

Ruby config options fail
Ruby is a horrible nightmare language, like almost all modern languages. They try to be so clever and modular, but end up making a maintenance hassle as various modules come and go, dependencies break, and the developer community moves on to the next shiny thing that claims to be the best thing to happen to programming since C.
Oh well.
If you get a bunch of "invalid option: --no-rdoc" errors, it is because sometime in the last few years --no-rdoc and --no-ri were depreciated in favor of --no-document. And, apparently, just recently builds started barfing on the deprecated errors. Building universally with these options is a pretty standard thing as it vastly improves build time and the rdoc system is a whole big kettle of annoying weirdness you just don’t need to wade through.
Now Ruby, being oh-so-clever and friendly, has all sorts of places where these might be set universally or semi-universally. The references will tell you about /.gemrc and /etc/gemrc, but only by doing a grep -FrHIis 'no-rdoc' * at / did I find these sneaky little bastards:
basejail/usr/ports/sysutils/vagrant/Makefile:RUBYGEM_ARGS= --no-ri --no-rdoc -l --no-update-sources \
basejail/usr/ports/Mk/Uses/gem.mk:RUBYGEM_ARGS+= --no-rdoc --no-ri
basejail/usr/ports/devel/ruby-gems/Makefile:DOCS_VARS_OFF= RUBY_SETUP_OPTIONS+="--no-ri --no-rdoc"
basejail/usr/ports/devel/rubygem-io-like/Makefile:DOCS_VARS_OFF= RUBYGEM_ARGS+=--no-rdoc
After converting those to the “new” “better” “shiny” version of the config option string did my gems build.