Self-publishing
Self-publishing and other vainglorious activities.
Convert A Slideshow/Presentation into HTML 5 Video
A seemingly common task would be to convert a talk or presentation given as a slide show into a playable video using a standards compliant format like WebM, which plays in almost all HTML 5 compliant browsers, that is just about everything but Safari on iOS (because Apple are walled garden asses) IE (because derp duh) and Opera Mini (because … well maybe too much work).
These days, WebM supports the pretty fantastic encoder AV1, which is the new thing that is genuinely open source and everyone should use for everything for this reason. It’s also absurdly slow to encode to, so maybe not everything, but it yields better results than VP9, which is also pretty decent. Compared to the H.series encoders (263/4/5/6), my results put VP9 between 4 and 5, depending on content and AV1 between 5 and 6, which is pretty solid and there aren’t too many tradeoffs with h/x.265 for most applications and you get FOSS freedom. Hopefully there will be much better hardware encoder support soon, though I’m sure we’re not gonna get that in iOS anytime soon. H.264 remains a pretty solid format for most use as it has broad and well optimized hardware compressors and decompressors. H.265 seems pretty well entrenched as well, but H.266 has been slow to pick up and very unscientifically I see AV1 as likely to undermine the H.266 adoption, though we’re still a long way from the necessary hardware for mobile/IoT devices to be confident of such an outcome yet.
I spent some time messing around with the process and testing various parameters. The fruit of that labor is as follows.
Export your slides into some useful format
The first step is exporting slides into a useful format like PNG. Assuming you have or can convert a presentation to PDF, then you can extract all the pages to individual files with pdfseparate, a command line tool that comes with poppler (which you’ll have because you run Inkscape, right? You should).
pdfseparate document.pdf %d.pdf
Then convert them to .png using inkscape like:
find . -type f -name "*.pdf" -exec inkscape "{}" --export-type=png --pdf-poppler -w 1920 -h 1440 -o "{}.png" \;
Set the width and height to meet your specific needs. Maybe 1920×1080? 1536×2160?
Extract or convert your audio file to wmv
This tutorial uses whisper to convert the audio file to text, which also makes it easy(ier) to get slide timings to about a second from the .vtt file whisper generates. The first step is converting the audio file to .wmv so whisper can eat it. I used ffmpeg (you need a recent version for AV1 support later so depending on distro, you might need to build it) to do this like
ffmpeg -hide_banner -i videofile.mkv -ac 1 audio.wav
Note that I am forcing mono audio with -ac 1 (and beware out of phase audio can cancel). I would expect most talks to not rely on stereo effects, but YMMV. Once you have this file and you’ve installed whisper (surprisingly easy), it will convert your long audio ramblings into equally (in)coherent text (the accuracy is surprisingly good) with a simple:
whisper audio.wav
At this point you should have a folder full of .png slides, an audio file of your talk in .wav, and a variety of text files in various text formats including a .vtt file that has time stamps in MM:SS.sss format and text and it is time for the first tedious bit. You need the from start HH:MM:SS.sss timing for each slide, plus the slide-to-slide timing in seconds (SSS), and it is helpful to have the from start seconds (SSSSSS) timing to verify key frame placement using ffprobe. Since Whisper’s .vtt file is only integer seconds, this isn’t going to be fractional second accurate timing, but good enough for slide transitions in a talk.
You could put this in a spreadsheet to automate the conversions from the .vtt’s format to the needed formats. I did it manually like this:
file 'QuantumComputingSlides1.png' duration 00:28 28 28 file 'QuantumComputingSlides2.png' duration 00:49 49 21 file 'QuantumComputingSlides3.png' duration 00:55 55 6 file 'QuantumComputingSlides4.png' duration 02:04 124 69 file 'QuantumComputingSlides5.png' duration 03:49 229 105
You have to convert all those time stamps into absolute seconds. I haven’t automated this yet, but it should be doable with a little regexp and bash or python if you have a lot of slides. If I do this with a talk that has enough slides to justify the effort, I’ll post a converter script.
Convert the Stills to Video Clips
This part assumes no fancy transitions, just jump cuts and that each slide is meant to be on-screen for some amount of time, the audio droning on over it and, perhaps, subtitles below it. This isn’t high art, mind you, just a utilitarian conversion for web viewing. The first step is to determine the slide transitions points, which you’ll need in absolute time format and in seconds/slide format, data which should be pretty easy to access from the speech-to-text .vtt file:
WEBVTT 00:00.000 --> 00:05.000 Okay, today's talk is going to be about quantum cryptography and quantum computing. (snip) 00:46.000 --> 00:49.000 So let's get right into it.
Slide one’s duration is 49 seconds and slide two should be shown at 00:00:49.000; collect this data for all the slides. Next, make text file for each slide that includes the slide file name (the .png file created earlier) and the duration (seconds on screen, not the absolute time). The files should look like this:
file 'QuantumComputingSlides3.png' duration 6 file 'QuantumComputingSlides3.png'
Slide 3 will be shown for 6 seconds. The file name appears twice around the duration because of some quirk in ffmpeg’s concat function. You should now have in your folder each slide as a .png file and for each slide a .txt file that describes the duration in file system sortable order (slide01.txt, slide02.txt etc).
I put the video encoding command in a bash script to make it a bit easier:
#!/bin/bash
# AV1 compression single pass
for i in *.txt
do name=`echo "$i" | cut -d'.' -f1`
ffmpeg -hide_banner -f concat -i "$i" -y -vf fps=10 -c:v libsvtav1 -pix_fmt yuv420p10le -preset 3 -svtav1-params tune=0:color-range=1:keyint=60000:scm=1 -b:v 0 -crf 40 -an "${name}.webm"
done
what the settings mean:
-vf fps=10 set the output video frame rate to 10fps. Why? Because timing works out. 5 might work too. -c:v libsvtav1 use the intel encoder, it is like 10x faster than libaom. -pix-fmt yuv420p10le use 10 bit encoding which makes gradients and dark areas better at a small cost, might as well. -preset 3 this determines encoding effort. 3 was manageable. 2 took a loong time. YMMV -stvav1-params this passes parameters through ffmpeg to the CODEC tune=0 tuned for content rather than PSNR tests color-range=1 full (computer) color rather than studio color keyint=60000 don't put in extra keyframes at all, just starting I then all P frames scm=1 peeps say 1 is good for digital graphics and maybe animation, 0 is default for live action -b:v 0 don't limit bandwidth (quality control only) -crf 40 this is a very low target quality because there's no motion to worry about -an no audio (for now)
Note that since iOS devices can’t do AV1 yet, it might be preferable to use the less efficient VP9 either as the sole version or as a fallback. This can be done with:
#!/bin/bash
# VP9 compression single pass
for i in *.txt
do name=`echo "$i" | cut -d'.' -f1`
ffmpeg -hide_banner -f concat -i "$i" -y -vf fps=10 -c:v libvpx-vp9 -pix_fmt yuv420p10le -deadline best -cpu-used 0 -b:v 0 -crf 40 -g 60000 -an "${name}.webm"
done
The options mean
-deadline best means to use the highest quality, slowest encoding -cpu-used 0 default is 0, but never hurts to be sure, best quality -g 60000 libvpx-vp9 uses the ffmpeg "g" to set keyframe intervals -lossless 1 seems like a good thing for slides, but yields quite large files
save and chmod+x and then execute
Once this finishes (and it will be a while with AV1) there will be a video file of the right number of seconds for each .png file. For my slides, the video clips are about 60-80% the size of the original png slides, because AV1 is much more efficient than .png even for still compression (like webp, based on vp9, which AV1 is the successor to).
The next step is to concatenate all the slide videos into a single video stream. First we create video list file from the folder of webm files like:
for f in *.webm; do echo "file '$f'" >> vidlist.txt; done
then we use ffmpeg again to merge the list into a single file like:
ffmpeg -hide_banner -f concat -safe 0 -i vidlist.txt -c copy slideshow.webm
what the command means:
-c copy Video streams are direct copied, no re-compression.
To verify the stream parameters you can use
ffprobe -hide_banner -select_streams v -show_entries frame=pict_type,pts_time -of csv=p=0 -i slideshow.webm | grep -v P
This should show a key frame at the cumulative seconds count (not H:M:S.MS format) for each slide change and no others (assuming there’s < 100 minutes per slide). Note this makes seeking really slow (REALLY slow) like 5 seconds to jump but to each slide is close to instant. You could use a standard value like “150” for the keyint meaning a keyframe every 15 seconds to speed up searching but at the cost of a lot of filesize.
The original png files were 9.3 MiB, the AV1 video conversion is 2.9MiB and the VP9 conversion is 3.1MiB. For a slide show, I’d argue that AV1 isn’t likely to be worth the extended encode time and compatibility issues, but YMMV and it is worth doing tests as results are very content dependent.
At this point you should have a video file without any audio and still have your .wav file plus your timing file. Next we’re going to add (back) the audio.
Adding Audio Back
This is a fairly straight forward, but we have to compress using an allowed codec for webm. I also keep the single channel and use a moderate data rate for speech.
ffmpeg -hide_banner -i slideshow.webm -i audio.wav -map 0 -map 1 -c:v copy -c:a libopus -b:a 48k -ac 1 presentation.webm
What the parameters mean:
-c:a libopus Use libopus, an allowed audio codec in webm -b:a 48k Compress at 48kbps, this is quite good for speech -ac 1 One audio track. If you're doing stereo, then default is fine
Now you have an audio video file, synced audio and slides and should be quite compact whether in VP9 or AV1, but it can be nice to add some metainformation including subtitles and chapter headings.
Adding subtitles back.
I suggest giving the whisper produced .vtt file at least a cursory edit. It is quite good, but can have trouble with homophones, which is understandable, especially with technical jargon. Once you’re happy with the text, you can merge the subs back into the webm container, tag the audio stream and subs with languages using:
ffmpeg -hide_banner -i presentation.webm -i audio.vtt -map 0:v -map 0:a -map 1:s \ -metadata:s:a language=eng -metadata:s:s:0 language=eng -c copy -y preso-sub.webm
what the parameters mean:
-map 0:v use the video from index 0 (first input) -map 0:a use the audio from index 0 (first input) -map 1:s use subtitles from index 1 (second input) -metadata:s:a language=eng the audio is english (or pick your lang) -metadata:s:s:0 language=eng the subs are english (or pick your lang)
Now your video file has subtitles and these should be selectable in VLC player
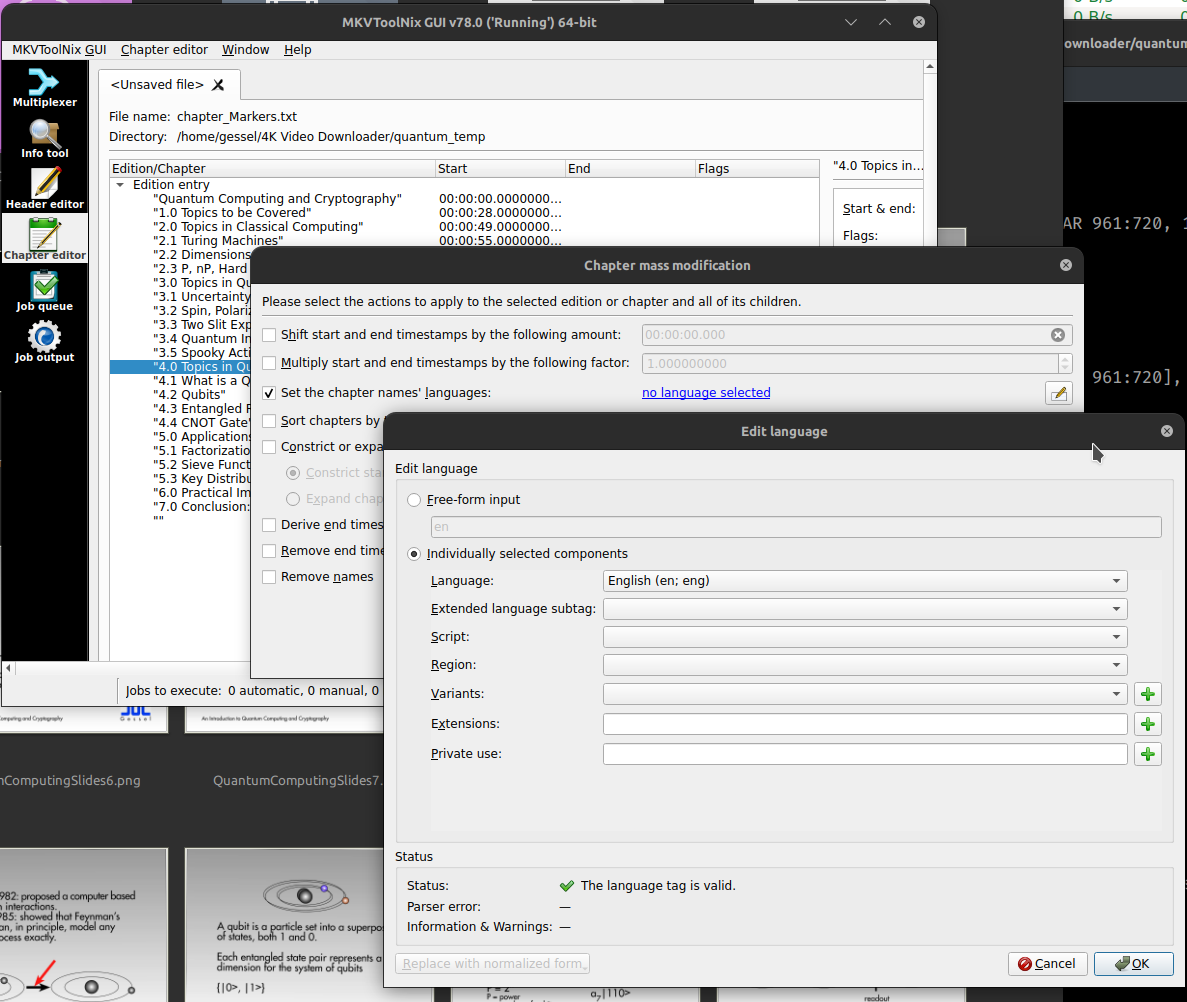
Add metadata and chapters with MKVToolNix
Chapter data and additional metadata is our first foray away from ffmpeg to another open source tool called MKVToolNix. Chapter data is easiest (and most reusable) by creating a chapter file using the slide timing data collected previous, but this time in absolute time in HH:MM:SS.sss so it looks like this (with the blank chapter at the out time of the whole video):
CHAPTER01=00:00:00.000 CHAPTER01NAME="Quantum Computing and Cryptography" CHAPTER02=00:00:28.000 CHAPTER02NAME="1.0 Topics to be Covered" ... CHAPTER22=00:50:07.000 CHAPTER22NAME="6.0 Practical Implementations" CHAPTER23=00:51:44.000 CHAPTER23NAME="7.0 Conclusion: Gessel's Law P=2^2^(Y/2) rev: P=2^2^(Y/3.4)" CHAPTER24=00:54:50.000 CHAPTER24NAME=""
You open this chapters.txt file in the Chapter Editor tab of MKVToolNix and then right click and select “additional modifications” then select the language. Finally, save from the “Chapter editor” menu (top of screen) and select “Save to Matroska or WebM file” and confirm that you’re going to overwrite the no-chapters version (with the addition of the chapter data).
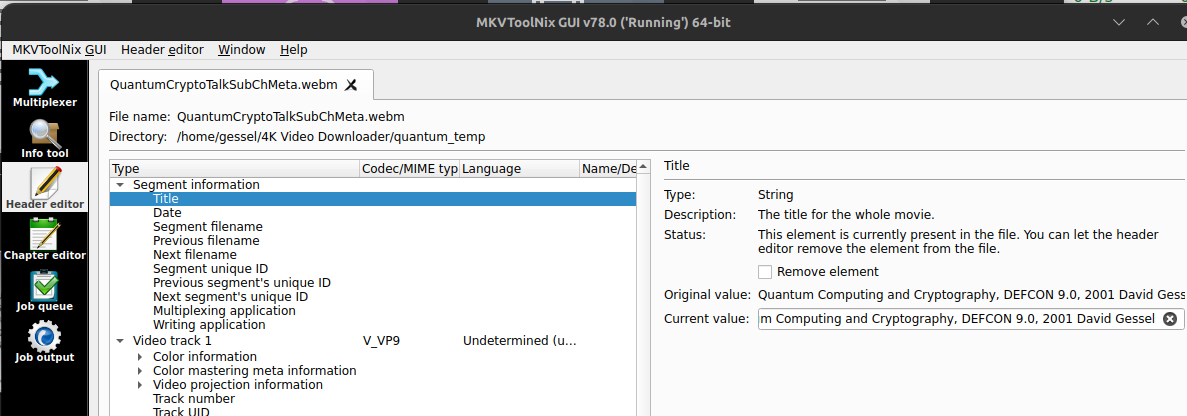
The last tidbit is to add some moderately useful metainformation, at least title and possible date (if relevant). Title, at least, is what’s used as the VLC title and possibly in other places. The MKVToolNix header editor tab will do what’s needed. You want to edit the “Segment information” – I’m not sure where the track information titles show up, so I don’t bother with them, but no harm in editing those either. Then just save with CTRL-S to update your WebM video with the additional metadata.
That’s it, you should now have a well-formatted, searchable, indexible video that will play directly from your own web server without relying on plugins or gifting your data to services like youtube or tiktok or whatever data harvesting service is luring the unwitting to data slaughter with Judas goats of convenience.
Sidebar featured images only on single post pages
After updating to WordPress 6.x and updating my theme (Clean Black based) and then merging the customizations back in with meld (yes, I really should do a child theme but this is a pretty simple theme so meld is fine), I didn’t really like the way the post thumbnails are shown, prefering to keep it to the right. I mean clean black was last updated in 2014 and while it still works fine, but that was a while ago. Plus I had hand-coded a theme sometime in the naughties and wanted to more or less keep it while taking advantage of some of the responsive features introduced about then.
Pretty much any question one might have, someone has asked it before, and I found some reasonable solutions, some more complex than others. There’s a reasonable 3 modification solution that works by creating another sidebar.php file (different name, same function) that gets called by single.php (and not the main page) that has the modification you want, but that seemed unnecessarily complicated. I settled on a conditional test is_singular which works to limit the get_the_post_thumbnail call to where I wanted and not to invoke it elsewhere. A few of the other options on the same stackexchange thread didn’t work for me, your install may be different. What I settled on (including a map call for geo-tagged posts) is:
<div id="sidebar">
<?php if (is_singular('post') ) {
echo get_the_post_thumbnail( $post->ID, 'thumbnail');
echo GeoMashup::map('height=150&width=300&zoom=5&add_overview_control=false&add_map_type_control=false&add_map_control=false');
} ?>
<div class="widgetarea">
<ul id="sidebarwidgeted">
<?php if (!dynamic_sidebar('Sidebar Top') ) : ?>
<?php endif; ?>
</ul>
</div>
</div>
And I get what i was looking for, a graphical anchor at the top of the single post (but not pages) for the less purely lexically inclined that didn’t clutter the home page or other renderings with a wee bit o php.
Favicon generation script
Favicons are a useful (and fun) part of the browsing experience. They once were simple – just an .ico file of the right size in the root directory. Then things got weird and computing stopped assuming an approximate standard ppi for displays, starting with mobile and “retina” displays. The obvious answer would be .svg favicons, but, wouldn’t’ya know, Apple doesn’t support them (neither does Firefox mobile) so for a few more iterations, it still makes sense to generate an array of sizes with code to select the right one. This little tool pretty much automates that from a starting .svg file.
There are plenty of good favicon scripts and tools on the interwebs. I was playing around with .svg sources for favicons and found it a bit tedious to generate the sizes considered important for current (2020-ish) browsing happiness. I found a good start at stackexchnage by @gary, though the sizes weren’t current recommended (per this github project). Your needs may vary, but it is easy enough to edit.
The script relies on the following wonderful FOSS tools:
- Inkscape to handle svg to png conversion
- Pngquant for png file optimization
- Imagemagick for conversion to .ico
These are available in most distros (software manager had them in Mint 19).
Note that my version leaves the format as .png – the optimized png will be many times smaller than the .ico format and png works for everything except IE<11, which nobody should be using anyway. The favicon.ico generated is 16, 32, and 48 pixels in 3 different layers from the 512×512 pixel version.
The command line options for inkscape changed a bit, the bash script below has been updated to reflect current.
Note: @Chewie9999 commented on https://github.com/mastodon/mastodon/issues/7396 that for Mastodon, the sizes needed would be generated with the following:
size=(16 32 36 48 57 60 72 76 96 114 120 144 152 167 180 192 256 310 384 512 1024)
The code below can be saved as a bash file, set execution bit, and call as ./favicon file.svg and off you go:
#!/bin/bash
# this makes the output verbose
set -ex
# collect the file name you entered on the command line (file.svg)
svg=$1
# set the sizes to be generated (plus 310x150 for msft)
size=(16 32 48 70 76 120 128 150 152 167 180 192 310 512)
# set the write director as a favicon directory below current
out="$(pwd)"
out+="/favicon"
mkdir -p $out
echo Making bitmaps from your svg...
for i in ${size[@]}; do
inkscape -o "$out/favicon-$i.png" -w $i -h $i $svg
done
# Microsoft wide icon (annoying, probably going away)
inkscape -o "$out/favicon-310x150.png" -w 310 -h 150 $svg
echo Compressing...
for f in $out/*.png; do pngquant -f --ext .png "$f" --posterize 4 --speed 1 ; done;
echo Creating favicon
convert $out/favicon-512.png -define icon:auto-resize=48,32,16 $out/favicon.ico
echo Done
Copy the .png files and .ico file generated above as well as the original .svg file into your root directory (or, if in a sub-directory, add the path below), editing the “color” of the Safari pinned tab mask icon. You might also want to make a monochrome version of the .svg file and reference that as the “mask-icon” instead, it will probably look better, but that’s more work.
The following goes inside the head directives in your index.html to load the correct sizes as needed (delete the lines for Microsoft’s browserconfig.xml file and/or Android’s manifest file if not needed.)
<!-- basic svg --> <link rel="icon" type="image/svg+xml" href="/favicon.svg"> <!-- generics --> <link rel="icon" href="favicon-16.png" sizes="16x16"> <link rel="icon" href="favicon-32.png" sizes="32x32"> <link rel="icon" href="favicon-48.png" sizes="48x48"> <link rel="icon" href="favicon-128.png" sizes="128x128"> <link rel="icon" href="favicon-192.png" sizes="192x192"> <!-- .ico files --> <link rel="icon" href="/favicon.ico" type="image/x-icon" /> <link rel="shortcut icon" href="/favicon.ico" type="image/x-icon" /> <!-- Android --> <link rel="shortcut icon" href="favicon-192.png" sizes="192x192"> <link rel="manifest" href="manifest.json" /> <!-- iOS --> <link rel="apple-touch-icon" href="favicon-76.png" sizes="76x76"> <link rel="apple-touch-icon" href="favicon-120.png" sizes="120x120"> <link rel="apple-touch-icon" href="favicon-152.png" sizes="152x152"> <link rel="apple-touch-icon" href="favicon-167.png" sizes="167x167"> <link rel="apple-touch-icon" href="favicon-180.png" sizes="180x180"> <link rel="mask-icon" href="/favicon.svg" color="brown"> <!-- Windows --> <meta name="msapplication-config" content="/browserconfig.xml" />
For WordPress integration, you don’t have access to a standard index.html file, and there are crazy redirects happening, so you need to append to your theme’s functions.php file with the below code snippet wrapped around the above icon declaration block (optimally your child theme unless you’re a theme developer since it’ll get overwritten on update otherwise):
/* Allows browsers to find favicons */
add_action('wp_head', 'add_favicon');
function add_favicon(){
?>
REPLACE THIS LINE WITH THE BLOCK ABOVE
<?php
};
Then, just for Windows 8 & 10, there’s an xml file to add to your directory (root by default in this example) Also note you need to select a color for your site, which has to be named “browserconfig.xml”
<?xml version="1.0" encoding="utf-8"?>
<browserconfig>
<msapplication>
<tile>
<square70x70logo src="/favicon-70.png"/>
<square150x150logo src="/favicon-150.png"/>
<wide310x150logo src="/favicon-310x150.png"/>
<square310x310logo src="/favicon-310.png"/>
<TileColor>#ff8d22</TileColor>
</tile>
</msapplication>
</browserconfig>
There’s one more file that’s helpful for mobile compatibility, the android save to desktop file, “manifest.json“. This requires editing and can’t be pure copy pasta. Fill in the blanks and select your colors
{
"name": "",
"short_name": "",
"description": "",
"start_url": "/?homescreen=1",
"icons": [
{
"src": "/favicon-192.png",
"sizes": "192x192",
"type": "image/png"
},
{
"src": "/favicon-512.png",
"sizes": "512x512",
"type": "image/png"
}
],
"theme_color": "#ffffff",
"background_color": "#ff8d22",
"display": "standalone"
}
Check the icons with this favicon tester (or any other).
Manifest validation: https://manifest-validator.appspot.com/
WebP and SVG
Using WebP coded images inside SVG containers works. I haven’t found any automatic way to do it, but it is easy enough manually and results in very efficiently coded images that work well on the internets. The manual process is to Base64 encode the WebP image and then open the .svg file in a text editor and replace the
xlink:href="data:image/png;base64, ..."
with
xlink:href="data:image/webp;base64,..."
(“…” means the appropriate data, obviously).
Back in about 2010 Google released the spec for WebP, an image compression format that provides a roughly 2-4x coding efficiency over the venerable JPEG (vintage 1974), derived from the VP8 CODEC they bought from ON2. VP8 is a contemporary of and technical equivalent to H.264 and was developed during a rush of innovation to replace the aging MPEG-II standard that included Theora and Dirac. Both VP8 and H.264 CODECs are encumbered by patents, but Google granted an irrevocable license to all patents, making it “open,” while H.264s patents compel licensing from MPEG-LA. One would think this would tend to make VP8 (and the WEBM container) a global standard, but Apple refused to give Google the win and there’s still no native support in Apple products.
A small aside on video and still coding techniques.
All modern “lossy” (throwing some data away like .mp3, as opposed to “lossless” meaning the original can be reconstructed exactly, as in .flac) CODECs are founded on either Discrete Cosine Transform (DCT) or Wavelet (DWT) encoding of “blocks” of image data. There are far more detailed write ups online that explain the process in detail, but the basic concept is to divide an image into small tiles of data then apply a mathematical function that converts that data into a form which sorts the information from least human-perceptible to most human-perceptible and sets some threshold for throwing away the least important data while leaving the bits that are most important to human perception.
Wavelets are promising, but never really took off, as in JPEG2000 and Dirac (which was developed by the BBC). It is a fairly safe bet that any video or still image you see is DCT coded thanks to Nasir Ahmed, T. Natarajan and K. R. Rao. The differences between 1993’s MPEG-1 and 2013’s H.265 are largely around how the data that is perceptually important is encoded in each still (intra-frame coding) and some very important innovations in inter-frame coding that aren’t relevant to still images.
It is the application of these clever intra-frame perceptual data compression techniques that is most relevant to the coding efficiency difference between JPEG and WebP.
Back to the good stuff…
Way back in 2010 Google experimented with the VP8 intra-coding techniques to develop WebP, a still image CODEC that had to have two core features:
- better coding efficiency than JPEG,
- ability to handle transparency like .png or .tiff.
This could be the one standard image coding technique to rule them all – from icons to gigapixel images, all the necessary features and many times better coding efficiency than the rest. Who wouldn’t love that?
Apple.
Of course it was Apple. Can’t let Google have the win. But, finally, with Safari 14 (June 22, 2020 – a decade late!) iOS users can finally see WebP images and websites don’t need crazy auto-detect 1974 tech substitution tricks. Good job Apple!
It may not be a coincidence that Apple has just released their own still image format based on the intra-frame coding magic of H.265, .heif and maybe they thought it might be a good idea to suddenly pretend to be an open player rather than a walled-garden-screw-you lest iOS insta-users wall themselves off from the 90% of the world that isn’t willing to pay double to pose with a fashionable icon in their hands. Not surprisingly, .heic, based on H.265 developments is meaningfully more efficient than WebP based on VP8/H.264 era techniques, but as it took WebP 10 years to become a usable web standard, I wouldn’t count on .heic having universal support soon.
Oh well. In the mean time, VP8 gave way to VP9 then to VP10, which has now AV1, arguably a generation ahead of HEVC/H.265. There’s no hardware decode (yet, as of end of 2020) but all the big players are behind it, so I expect 2021 devices will and GPU decode will come in 2021. By then, expect VVC (H.266) to be replacing HEVC (H.265) with a ~35% coding efficiency improvement.
Along with AV1’s intra/inter-frame coding advance, the intra-frame techniques are useful for a still format called AVIF, basically AVIF is to AV1 (“VP11”) what WEBP is to VP8 and HEIF is to HEVC. So far (Dec 2020) only Chrome and Opera support AVIF images.
Then, of course, there’s JPEG XL on the way. For now, the most broadly supported post-JPEG image codec is WEBP.
SVG support in browsers is a much older thing – Apple embraced it early (SVG was not developed by Google so….) and basically everything but IE has full support (IE… the tool you use to download a real browser). So if we have SVG and WebP, why not both together?
Oddly I can’t find support for this in any of the tools I use, but as noted at the open, it is pretty easy. The workflow I use is to:
- generate a graphic in GIMP or Photoshop or whatever and save as .png or .jpg as appropriate to the image content with little compression (high image quality)
- Combine that with graphics in Inkscape.
- If the graphics include type, convert the type to SVG paths to avoid font availability problems or having to download a font file before rendering the text or having it render randomly.
- Save the file (as .svg, the native format of Inkscape)
- Convert the image file to WebP with a reasonable tool like Nomacs or Ifranview.
- Base64 encode the image file, either with base64
# base64 infile.webp > outfile.webp.b64or with this convenient site - If you use the command line option the prefix to the data is “
data:image/webp;base64,“ - Replace the … on the appropriate
xlink:href="...."with the new data using a text editor like Atom (RIP). - Drop the file on a browser page to see if it works.
WordPress blocks .svg uploads without a plugin, so you need one
The picture is 101.9kB and tolerates zoom quite well. (give it a try, click and zoom on the image).

Open letter to the FCC 5 regarding net neutrality
I’m in favor of net neutrality for a lot of reasons; a personal reason is that I rely on fair and open transport of my bits to work overseas. If you happen to find this little screed, you can also thank net neutrality for doing so as any argument for neutrality will likely be made unavailable by the ISPs that should charge exorbitant rents for their natural monopolies and would be remiss in their fiduciary responsibility should they fail to take every possible step to maximize shareholder value, for example by permitting their customers access to arguments contrary to their financial or political interests.
I sent the following to the FCC 5. I am not, I’m sorry to say, optimistic.
Please protect Net Neutrality. It is essential to my ability to operate in Iraq, where I run a technical security business that relies on access to servers and services in the United States. If access to those services becomes subject to a maze of tiered access limitations and tariffs, rather than being treated universally as flat rate data, my business may become untenable unless I move my base of operations to a net neutrality-respecting jurisdiction. The FCC is, at the moment, the only bulwark against a balkanization of data and the collapse of the value premise of the Internet.
While I understand and am sympathetic to both a premise that less government regulation is better in principal and that less regulated markets can be more efficient; this “invisible hand” only works to the benefit in a “well regulated market.” There are significant cases where market forces cannot be beneficial, for example, where the fiduciary responsibility of a company to maximize share-holder value compels exploitation of monopoly rents to the fullest extent permitted by law and, where natural monopolies exist, only regulation prevents those rents from becoming abusive. Delivery of data services is a clear example of one such case, both due to the intrinsic monopoly of physical deployment of services through public resources and due to inherent opportunities to exert market distorting biases into those services to promote self-beneficial products and inhibit competition. That this might happen is not idle speculation: network services companies have routinely attempted to unfairly exploit their positions to their benefit and to the harm of fair and open competition and in many cases were restrained only by existing net neutrality laws that the FCC is currently considering rescinding. The consequences of rescinding net neutrality will be anti-competitive, anti-productive, and will stifle innovation and economic growth.
While it is obvious and inevitable that network companies will abuse their natural monopolies to stifle competition, as they have attempted many times restrained only by previous FCC enforcement of the principal of net neutrality, rescinding net neutrality also poses a direct risk to the validity of democracy. While one can argue that Facebook has already compromised democracy by becoming the world’s largest provider of news through an extraordinarily easily manipulated content delivery mechanism, there’s no evidence that they have yet exploited this to achieve any particular political end nor actively censored criticism of their practices. However, without net neutrality there is no legal protection to inhibit carriers from exploiting their control over content delivery to promote their corporate or political interests while censoring embarrassing or opposing information. As the vast majority of Americans now get their news from on-line resources, control over the delivery of those resources becomes an extraordinarily powerful political weapon; without net neutrality it is perfectly legal for corporations to get “their hands on those weapons” and deploy them against their economic and political adversaries.
Under an implicit doctrine of net neutrality from a naive, but then technically accurate, concept of the internet as a packet network that would survive a nuclear war and that would treat censorship as “damage” and “route around it automatically,” to 2005’s Madison River ruling, to the 2008 Comcast ruling, to 2010’s Open Internet Order the internet has flourished as an open network delivering innovative services and resources that all businesses have come to rely on fairly and equally. Overturning that historical doctrine will result in a digital communications landscape in the US that resembles AT&Ts pre-breakup telephone service: you will be permitted to buy only the services that your ISP deems most profitable to themselves. In the long run, if net neutrality is not protected, one can expect the innovation that has centered in the US since the birth of the internet, which some of us remember as the government sponsored innovation ARPAnet, to migrate to less corporatist climates, such as Europe, where net neutrality is enshrined in law.
The American people are counting on you to protect us from such a catastrophic outcome.
Do not reverse the 2015 Open Internet Order.
Sincerely,
David Gessel
cc:
Mignon.Clyburn@fcc.gov
Brendan.Carr@fcc.gov
Mike.O’Reilly@fcc.gov
Ajit.Pai@fcc.gov
Jessica.Rosenworcel@fcc.gov
Kitty Poop (1995)
Many years ago (21 years, 9 months as of this post), I used some as-of-then only slightly out of date equipment to record a one week time lapse of the cats’ litter box.
I found the video on a CD-ROM (remember those?) and thought I’d see if it was still usable. It wasn’t – Quicktime had abandoned support for most of the 1990’s era codecs, and as it was pre-internet, there just wasn’t any support any more. I had to fire up my old Mac 9500, which booted just fine after years of sitting, even if most of the rubber feet on the peripherals had long since turned to goo. The OS9 version of QT let me resave as uncompressed, which of course was way too big for the massive dual 9GB drives in that machine. Youtube would eat the uncompressed format and this critical archival record is preserved for a little longer.
Time lapse of the litter box. Shot in Sept, 1995 in San Francisco, CA. Captured with a RasterOps ColorBoard 364 Nubus card from a Sony XC-999 on a Mac IIfx.
Yahoo account PSA

It seems that if you have a yahoo mail account it either already has or will soon be hacked. There’s some news out there about this…..
Yes, how could you not be sure that when somebody offers to host your personal data for free on their servers that nothing could possib-lie go wrong. Uh, PossibLY go wrong.