Deep Learning Image Compression: nearly 10,000:1 compression ratio!
Here disclosed is a novel compression technique I call Deep Learning Semantic Vector Quantization (DLSVC) that achieves in this sample 9,039:1 compression! Compare this to JPEG at about 10:1 or even HEIC at about 20:1, and the absolutely incredible power of DL image compression becomes apparent.
Before I disclose the technique to achieve this absolutely stunning result, we need to understand a bit about the psychovisual mechanisms that are being exploited. A good starting point is thinking about:
It was a dark and stormy night and all through the house not a creature was stirring, not even a mouse.
I’m sure each person reading this develops an internal model, likely some combination of a snug, warm indoor Christmas scene while outside a storm raged, or something to that effect derived from the shared cultural semantic representation: a scene with a great deal of detail and complexity, despite the very short text string. The underlying mechanism is a sort of vector quantization where the text represents a series of vectors that semantically reference complex culturally shared elements that form a type of codebook.
If a person skilled at drawing were to attempt to represent this coded reference visually, it is likely the result would be recognizable to others as a representation of the text; that is, the text is an extremely compact symbolic representation of an image.
So now lets try a little AI assisted vector quantization of images. We can start with the a generic image from Wikipedia:
{kind=link}
Next we use AI to reduce the image to a symbolic semantic representation. There are far more powerful AI systems available, but we’ll use one that allows normal people to play with it, @milhidaka’s caption generator on github:
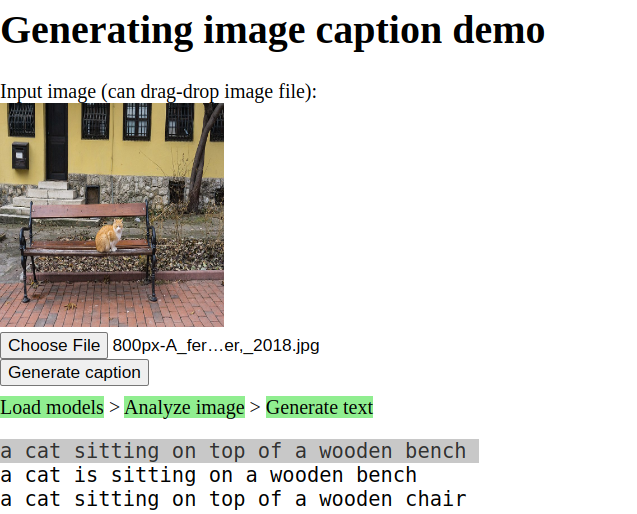
This is a cat sitting on top of a wooden bench which we can LZW compress assuming 26 character text to a mere 174 bits or 804D22134C834638D4CE3CE14058E38310D071087. That’s a pretty compact representation of an image! The model has been trained to understand a correlation between widely shared semantic symbols and elements of images and can reduce an image to a human-comprehensible, compact textual representation, effectively a lossy coding scheme referencing a massive shared codebook with complex grammatical rules that further increase the information density of the text.
Decoding those 174 bits back to the original text, we can feed them into an image generating generative AI model, like DALL·E mini and we get our original image back by reversing the process leveraging a different semantic model, but one also trained to the same human language.
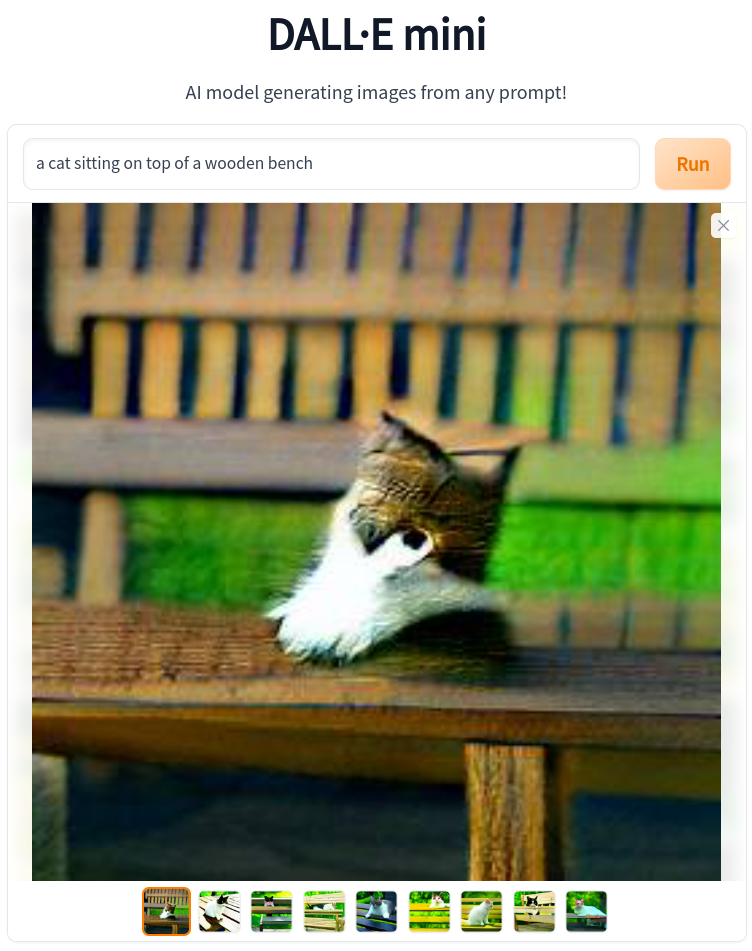
It is clearly a lossy conversion, but here’s the thing: so too is human memory lossy. If you saw the original scene and 20 years later, someone said, “hey, remember that time we saw the cat sitting on a wooden bench in Varna, look, here’s a picture of it!” and showed you this picture, I mean aside from the funny looking cat like blob, you’d say “oh, yeah, cool, that was a cute cat.”
Using the DALL·E mini output as the basis for computing compression rather than the input image which could be arbitrarily large, we have 256×256×8×3 bits output = 1,572,864 bits to represent the output image raw.
WebP “low quality” compressing the 256×256 image yields a file of 146,080 bits or 10.77:1 compression.
My technique yields a compressed representation of 174 bits or 9,039:1 compression. DALL·E 2‘s 1024×1024 output size should yield 144,624:1 compression.
This is not a photograph. This is Dall-E 2’s 25,165,824 bit (raw) interpretation of the 174 bit text “a cat sitting on top of a wooden bench” which was derived by a different AI from the original image.
So just for comparison, lets consider how much we can compress the original image, resizing to 32×21 pixels and, say, webp, to 580 bytes.
 Even being generous and using the original file’s 7,111,400 bytes such that this blancmange of an image represents 12,261:1 compression, it is still 12× worse compression than our novel technique, it is hard to argue that this is a better representation of the original image than our AI-based semantic codebook compression achieved.
Even being generous and using the original file’s 7,111,400 bytes such that this blancmange of an image represents 12,261:1 compression, it is still 12× worse compression than our novel technique, it is hard to argue that this is a better representation of the original image than our AI-based semantic codebook compression achieved.
Pied Piper got nothin’ on this!
Audio Compression for Speech
Speech is generally a special class of audio files where compression quality is rated more on intelligibility than on fidelity, though the two related the former may be optimized at the expense of the latter to achieve very low data rates. A few codecs have emerged as particularly adept at this specific class: Speex, Opus, and the latest, Google’s Lyra, a deep learning enhanced codec.
Lyra is focused on Android and requires a bunch of Java cruft to build and needs debugging. It didn’t seem worth the effort, but I appreciate the Deep Learning based compression, it is clearly the most efficient compression possible.
I couldn’t find a quick whatcha-need-to-know is kind of summary of the codecs, so maybe this is useful:
Opus
On Ubuntu (and most Linux distros) you can install the Opus codec and supporting tools with a simple
# sudo apt install opus-tools
If you have ffmpeg installed, it provides a framework for dealing with IO and driving libopus from the command line like:
# ffmpeg -i infile.mp3 -codec:a libopus -b:a 8k -cutoff 8000 outfile.opus
Aside from infile.(format) and outfile.opus, there are two command line options that make sense to mess with to get good results: the bitrate -b:a (bit rate) and the -cutoff (frequency), which must be 4000 (narrowband), 6000 (mediumband), 8000 (wideband), 12000 (super wideband), or 20000 (fullband). The two parameters work together and for speech limiting bandwidth saves bits for speech.
There are various research papers on the significance of frequency components in speech intelligibility that range from about 4kHz to about 8kHz (and “sometimes higher”). I’d argue useful cutoffs are 6000 and 8000 for most applications. The fewer frequency components fed into the encoder, the more bps remain to encode the residual. There will be an optimum value which will maximize the subjective measure of intelligibility times the objective metric of average bit rate that has to be determined empirically for recording quality, speaker’s voice, and transmission requirements.
In my tests, my sample, the voice I had to work with an 8kHz bandwidth made little perceptible difference to the quality of speech. 6kbps VBR (-b:a 6k) compromised intelligibility, 8k did not, and 24k was not perceptibly compromised from the source.
one last option to consider might be the -application, which yields subtle differences in encoding results. The choices are voip which optimizes for speech, audio (default) which optimizes for fidelity, and lowdelay which minimizes latency for interactive applications.
# ffmpeg -i infile.mp3 -codec:a libopus -b:a 8k -application voip -cutoff 8000 outfile.opus
VLC player can play .opus files.
Speex
AFAIK, Speex isn’t callable by ffmpeg yet, but the speex installer has a tool speexenc that does the job.
# sudo apt install speex
Speexenc only eats raw and .wav files, the latter somewhat more easily managed. To convert an arbitrary input to wav, ffmpeg is your friend:
# ffmpeg -i infile.mp3 -f wav -bitexact -acodec pcm_s16le -ar 8000 -ac 1 wavfile.wav
Note the -ar 8000 option. This sets the sample rate to 8000 – Speexenc will yield unexpected output data rates unless sample rates are 8000, 16000, or 32000, and these should correlate to the speexenc bandwidth options that will be used in the compression step (speexenc doesn’t transcode to match): -n “narroband,” -w “wideband,” and -u “ultrawideband”
# speexenc -n --quality 3 --vbr --comp 10 wavfile.wav outfile.spx
This sets the bandwidth to “narrow” (matching the 8k input sample rate), the quality to 3 (see table for data rates), enables VBR (not enabled by default with speex, but it is with Opus), and the “complexity” to 10 (speex defaults to 3 for faster encode, Opus defaults to 10), thus giving a pretty head-to-head comparison with the default Opus settings.
VLC can also play speex .spx files. yay VLC.
Results
The result is an 8kbps stream which is to my ear more intelligible than Opus at 8kbps – not 😮 better, but 😐 better. This is atypical, I expected Opus to be obviously better and it wasn’t for this sample. I didn’t carefully evaluate the -application voip option, which would likely tip the tables results. Clearly YMMV so experiment.