html
A one page home/new tab page with random pictures, time, and weather
Are you annoyed by a trend in browsers to default to an annoying advertising page with new tabs? I sure am. And they don’t make it easy to change that. I thought, rather than a blank new tab page, why not load something cute and local. I enlisted claude.ai to help expedite the code and got something I like.
homepage.html is a very simple default page that loads a random image from a folder as a background, overlays the current local time in the one correct time format with seconds, live update, and throws up the local weather from wttr.in after a delay (to avoid hitting the server unnecessarily if you’re not going to keep the tab blank long enough to see the weather).
Images have to be in a local folder and in a predictable naming structure, as written “image_001.webp” to “image_999.webp.” If the random enumerator chooses an image name that doesn’t exist, you get a blank page.
Browsers don’t auto-rotate by exif (or webp) metadata, so orient all images in the folder as you’d like them to appear.
The weather information is only “current” which isn’t all that useful to me, I’d like tomorrows weather, but that’s not quite possible with the one-liner format yet.
How you set the homepage and new tab default page varies by browser. In Brave try hamburger->appearance->show home button->select option->paste the location of the homepage.html file, e.g. file://home/gessel/homepage.html.
The pictures are up to you, but here’s the code:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>New Tab</title>
<style>
body {
margin: 0;
padding: 0;
height: 100vh;
display: flex;
justify-content: center;
align-items: flex-start;
overflow: hidden;
}
#background-image {
position: fixed;
top: 0;
left: 0;
width: 100%;
height: 100%;
background-size: cover;
background-position: center;
z-index: -1;
}
#time-date {
position: absolute;
top: 20px;
right: 20px;
font-size: 48px;
color: white;
text-shadow: 3px 3px 8px rgba(0, 0, 0, 1);
font-family: sans-serif;
font-weight: bold;
}
#weather {
position: absolute;
bottom: 20px;
left: 20px;
font-size: 24px;
color: white;
text-shadow: 3px 3px 8px rgba(0, 0, 0, 1);
font-family: sans-serif;
}
</style>
</head>
<body>
<div id="background-image"></div>
<div id="time-date"></div>
<div id="weather"></div>
<script>
// Function to get a random image from the 'image_001.webp' to 'image_230.webp' range
// Edit image folder to match the folder you want to store the images in
// edit the min and max image index range to match the images
// set the imageName extension to suit (e.g. .jpg, .webp, .png)
// white screen usually means the images or folder can't be found
function getRandomImage() {
const imageFolder = '.images/';
const minImageIndex = 1;
const maxImageIndex = 230;
const randomIndex = Math.floor(Math.random() * (maxImageIndex - minImageIndex + 1)) + minImageIndex;
const imageName = `image_${randomIndex.toString().padStart(3, '0')}.webp`;
return `${imageFolder}${imageName}`;
}
// Function to update the time and date display
// Updates every second, uses the only technically correct* date and time format
// * The best kind of correct.
function updateTimeDate() {
const dateTimeElement = document.getElementById('time-date');
const currentDate = new Date();
const year = currentDate.getFullYear();
const month = String(currentDate.getMonth() + 1).padStart(2, '0');
const day = String(currentDate.getDate()).padStart(2, '0');
const hours = String(currentDate.getHours()).padStart(2, '0');
const minutes = String(currentDate.getMinutes()).padStart(2, '0');
const seconds = String(currentDate.getSeconds()).padStart(2, '0');
const formattedDateTime = `${year}-${month}-${day} ${hours}:${minutes}:${seconds}`;
dateTimeElement.textContent = formattedDateTime;
}
// Function to fetch and display the weather information
// The delay is set for 10 seconds to avoid hitting the wttr.in server if you're just
// opening a tab to enter a web address. Hopefully one-line forcasts will be implemented
// soon - check https://github.com/chubin/wttr.in/issues/447 for progress
async function updateWeather() {
const weatherElement = document.getElementById('weather');
try {
await new Promise(resolve => setTimeout(resolve, 10000)); // 10-second delay
const response = await fetch('https://wttr.in/?m&format=%l%20%c+%C+%t%20+%h%20+%w\n');
const weatherData = await response.text();
weatherElement.textContent = weatherData;
} catch (error) {
console.error('Error fetching weather information:', error);
weatherElement.textContent = 'Error fetching weather information.';
}
}
// Set the random background image
const backgroundImage = document.getElementById('background-image');
backgroundImage.style.backgroundImage = `url('${getRandomImage()}')`;
// Update the time and date every second
setInterval(updateTimeDate, 1000);
// Update the weather information every 100 minutes
updateWeather();
setInterval(updateWeather, 6000000);
// thanks to claude.ai for helping with the scripts.
</script>
</body>
</html>
Overthrow the Cert Mafia!
The certificate system is badly broken on a couple of levels and the most recent revelation that Turktrust accidentally issued two intermediate SSL CAs which enabled the recipients to issue presumptively valid arbitrary certificates. This is just the most recent (probably the most recent, this seems to happen a lot) compromise in a disastrously flawed system including the recent Diginotar and Comodo attacks. There are 650 root CAs that can issue certs, including some CA‘s operated by governments with potentially conflicting political interests or poor human rights records and your browser probably trusts most or all completely by default.
It is useful to think about what we use SSL certs for:
- Establishing an encrypted link between our network client and a remote server to foil eavesdropping and surveillance.
- To verify that the remote server is who we believe it to be.
Encryption is by far the most important, so much more important than verification that verification is almost irrelevant, and fundamental flaws with verification in the current CA system make even trying to enforce verification almost pointless. Most users have no idea what what any of the cryptic (no pun intended) and increasingly annoying alerts warning of “unvalidated certs” mean or even what SSL is.
Google recently started rejecting self-signed certs when attempting to establish an SSL encrypted POP connection via Gmail, an idiotically counterproductive move that will only make the internet less secure by forcing individual mail servers to connect unencrypted. And this is from the company who’s cert management between their round-robin servers is a total nightmare and there’s no practical way to ever be sure if a connection has been MITMed or not as certs come randomly from any number of registrars and change constantly.

What I find most annoying is that the extraordinary protective value of SSL encrypted communication is systematically undermined by browsers like Firefox in an intrinsically useless effort to convince users to care about verification. I have never, not once, ever not clicked through SSL warnings. And even though I often access web sites from areas that are suspected of occasionally attempting to infiltrate dissident organizations with MITM attacks, I still have yet to see a legit MITM attack in the wild myself. But I do know for sure that without SSL encryption my passwords would be compromised. Encryption really matters and is really important to keeping communication secure; anything that adds friction to encryption should be rejected. Verification would be nice if it worked, but don’t add friction to encryption.

Self-signed certs and community verified certs (like CAcert.org) should be accepted without any warnings that might slow down a user at all so that all websites, even non-commercial or personal ones, have as little disincentive to adding encryption as possible. HTTPSEverywhere, damnit. Routers should be configured to block non-SSL traffic (and HTML email, but that’s another rant. Get off my lawn.)
Verification is unsolvable with SSL certs for a couple of reason, some due to the current model, some due to reasonable human behavior, some due to relatively legitimate law-enforcement concerns, but mostly because absolute remote verification is probably an intractable problem.

Even at a well run notary, human error is likely to occur. A simple typo can, because registrar certs are by default trusted globally, compromise anyone in the world. One simple mistake and everybody is at risk. Pinning does not actually reduce this risk as breaks have so far been from generally well regarded notaries, though rapid response to discovered breaches can limit the damage. Tools like Convergence, Perspectives, and CrossBear could mitigate the problem, but only if they have sufficiently few false positives that people pay attention to the warnings and are built in by default.
But even if issuance were somehow fixed with teams of on-the-ground inspectors and biometrics and colonoscopies, it wouldn’t necessarily help. Most people would happily click through to www.bankomerica.com without thinking twice. Indeed, as companies may have purchased almost every spelling variation and point them all toward their “most reasonable” domain name, it isn’t unreasonable to do so. If bankomerica.com asked for a cert in Ubeki-beki-beki-stan-stan, would they (or even should they) be denied? No – valid green bar, invalid site. Even if misdirections were non-SSL encrypted, it isn’t practical to typo-test every legit URL against every possible fake, and the vast majority of users would never notice if their usual bank site came up unencrypted one day with a DNS attack to a site not even pretending to fake a cert (in fact, studies suggest that no users would notice). This user limitation fundamentally obviates the value of certs for identifying sites. But even a typo-misdirection is assuming too much of the user – all of my phishing spam uses brand names in anchortext leading to completely random URLs, rarely even reflective of the cover story, and the volume of such spam suggests this is a perfectly viable attack. Verification attacks don’t even need to go to a vaguely similar domain let alone go to all the trouble of attacking SSL.

One would hope that dissidents or political activists in democracy challenged environments that may be subject to MITM attacks might actually pay attention to cert errors or use perspectives, convergence, or crossbear. User education should help, but in the end you can’t really solve the stupid user problem with technology. If people will send bank details to Nigeria so that a nationality abandoned astronaut can expatriate his back pay, there is no way to educate them on the difference between https://www.bankofamerica.com and http://www.bankomerica.com. The only useful path is to SSL encrypt all sites and try to verify them via a distributed trust mechanism as implemented by GPG (explicit chain of trust), Perspectives (wisdom of the masses), or Convergence (consensus of representatives); all of these seem infinitely more reliable than trusting any certificate registry, whether national or commercial and as a bonus they escape the cert mafia by obviating the need for a central authority and the overhead entailed; but this only works if these tools have more valid positives than false positives, which is currently far from the case.

Further, law enforcement makes plausible arguments for requiring invisible access to communication. Ignoring the problematic but understandable preference for push-button access without review and presuming that sufficient legal barriers are in place to ensure such capabilities protect the innocent and are only used for good, it is not rational to believe that law enforcement will elect to give up on demanding lawful intercept capabilities wherever possible. Such intercept is currently enabled by law enforcement certificates which permit authorized MITM attacks to capture encrypted data without tipping off the target of the investigation. Of course, if the US has the tool, every other country wants it too. Sooner or later, even with the best vetting, there is a regime change and control of such tools falls into nefarious hands (much like any data you entrust to a cloud service will sooner or later be sold off in an asset auction to whoever can scrape some residual value out of your data under whatever terms suit them, but that too is a different rant). Thus it is not reasonable for activists in democracy challenged environments to assume that SSL certs are a secure way to ensure their data is not being surveilled. Changing the model from intrinsic, automatic trust of authority to a web-of-trust model would substantially mitigate the risk of lawful intercept certs falling into the wrong hands, though also making such certs useless or far harder to implement.
There is no perfect answer to verification because remote authentication is Really Hard. You have to trust someone as a proxy and the current model is to trust all or most of the random, faceless, profit or nefarious motive driven certificate authorities. Where verification cannot be quickly made and is essential to security, out of band verification is the only effective mechanism such as transmitting a hash or fingerprint of the target’s cryptographic certificate via voice or postal mail or perhaps via public key cryptography.
Sadly, the effort to prop up SSL as a verification mechanism has been made at the compromise of widespread, low friction encryption. False security is being promoted at the expense of real security.
That’s just stupid.
Working Toward Workable Time Zones
PIMs (Personal Information Managers, what we used to call things like Outlook, or Sunbird, or Lightning, or Zimbra before they were integrated with email) haven’t progressed much in the last 20 or so years. Actually, neither have email clients. Perhaps the most essential of our daily tools, these classes of products have failed to progress much at all over the decades.
Sure, email has styled text now and you can compose a message in Outlook using Word, but these wizzy tricks distract from the function of email–communicating the written word. There’s rarely any reason to style text in email and HTML mail has only been a boon for spammers and a distraction for users. One of the few useful enhancements is inline images which I do find useful.
The best email clients ever, Eudora and Mulberry (the BAT might qualify too, though I haven’t used it) have failed to keep up in OS level support. Thunderbird is OK, and pimped out with extensions to enable proper formatting, forwarding, text wrapping, etc. it is usable, though it still doesn’t handle frequent IMAP disconnections all that gracefully (it pains me to admit it, but only Outlook does this really well).
PIM functionality has actually gone backwards as the years have gone by. Calendar programs have always handled reminders and notifications and scheduled events fairly well. DateBook was great in 1990 and there’s very little useful that has been added since . In the mid-90’s Motorola shipped a great little PIM along with their TimePort phones called TrueSync Desktop. You could create an event in a time zone other than the one you were in. Wow. Amazing. The developers actually considered the possibility that you, the user, might have some business in a time zone other than the one you’re in. At the time, some people pointed to Outlook’s then “dual time zone” functionality as the be-all end-all. True, two time zones are better than one, but hardly a solution suitable for the whole of the US, let alone the world and the pixel heavy dual time zone stripe precluded anything more comprehensive. At the time, the official M$ work-around was to change your computer’s time zone to the time zone you wanted to create the event in, create the event, then change the time zone back. Brilliant.
Lightning (for Thunderbird) and Sunbird (stand alone) Calendar programs have finally incorporated some timezone functionality, you can at least set the starting and ending time zone of an event independently and differently from the time zone you’re in:
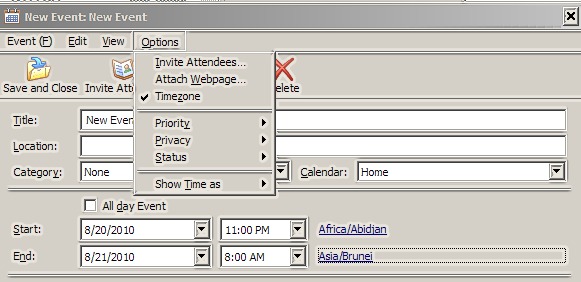
It is a start, but the time zone picker is still pretty much unusable:
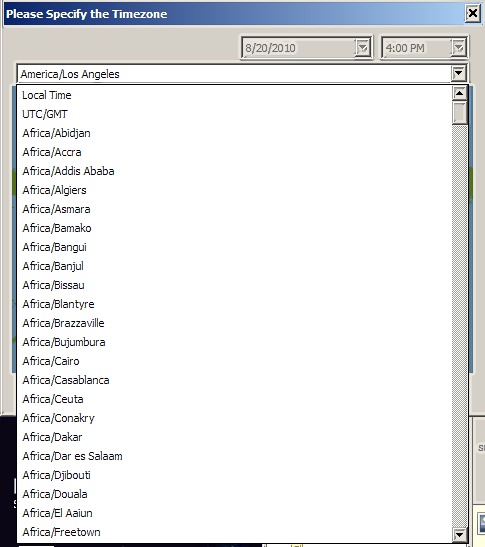
This is a huge enhancement though, one I’ve been pushing for a long time:
https://bugzilla.mozilla.org/show_bug.cgi?id=224905
https://bugzilla.mozilla.org/show_bug.cgi?id=364750
https://bugzilla.mozilla.org/show_bug.cgi?id=364751
https://bugzilla.mozilla.org/show_bug.cgi?id=364751
The right answer is a simple pop-up menu with my favorite time zones in it. I can use the semi-infinite list of seemingly random city names as a geography quiz along with Wikipedia to figure out what my favorite time zones are as long as I don’t have to spend 10 minutes scrolling through them every time I’m trying to find America/New York for ET or America/Los Angeles for PT (or America/Dawson Creek for MST, no DST).
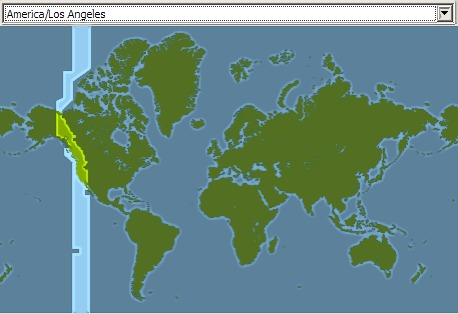
Oddly, Lightning actually has a half-decent map view that shows you the time zone you’ve selected, but you can’t click on it to pick the time zone you want (!?):
I really like worldtimezone‘s view as a graphical picker:
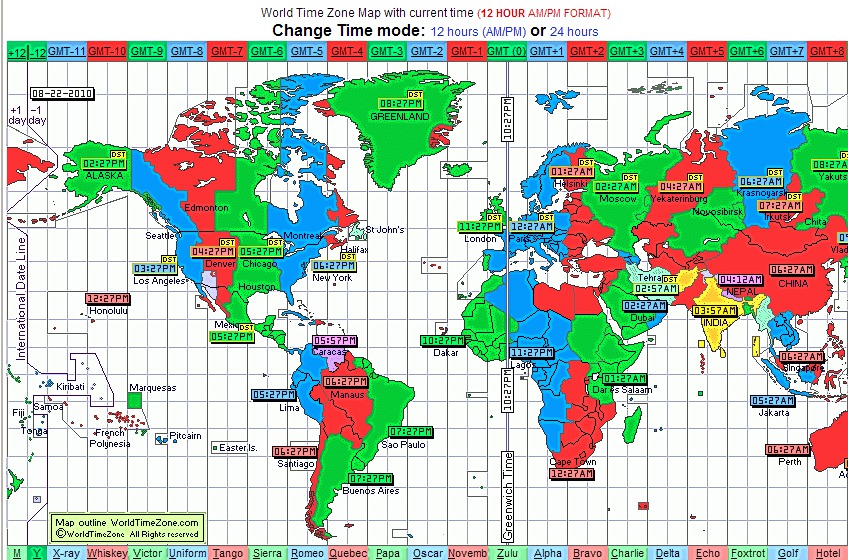
Something like this, plus a search tool into a database of time zones for cities would be just perfect for creating my list of favorite time zones. Even the most worldly traveler is unlikely to need more than a dozen time zones in their favorites list and thus a popup would make selecting the start and end time zones very straight-forward. Way back at the start of 2007 I proposed something like:
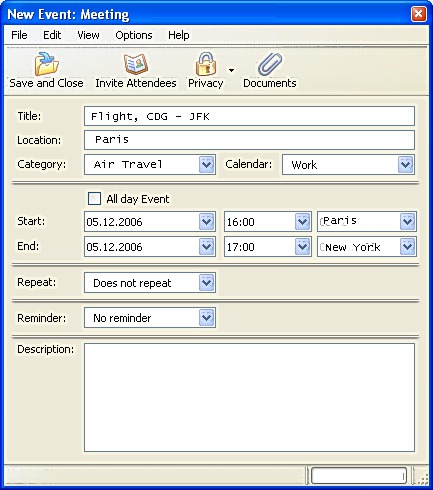
Which is pretty much a copy of Starfish’s TrueSync Desktop (though TSD didn’t support different starting and ending time zones). Someday… maybe someday I’ll have a calendar program as advanced as they were in 1993.
UPDATE 2023:
It took about 7 years or so to finally get this into release Thunderbird, but time zones are now workable. Thanks devs! Open source software rocks.
![]()
Also, even more recently, we FINALLY got ISO 8601 (like, not quite standard since that requires an icky date/time delimiter rather than a readable ” “) time as a universally selectable date/time format. It took about 6 years, but has been a problem much longer. It is just that for a decade or so, one could select Denmark as a rational date structure and then that broke and we had stupid date formats for years until the devs put in an awesome fix.
https://bugzilla.mozilla.org/show_bug.cgi?id=1509096
https://bugzilla.mozilla.org/show_bug.cgi?id=1426907
Lookin’ good!
![]()
What up with the “+” Google?
<meta content=”text/html; charset=ISO-8859-1″
http-equiv=”Content-Type”>
Type “Log Viewer” (without the quotes) and get “Log+Viewer.” It seems
like an operator that would force adjacency, but it doesn’t seem to.
“Log AND Viewer” becomes “Log+AND+Viewer” (the explicit operator isn’t
parsed) and “”log viewer”” becomes “”log+viewer”” so it seems the space
is being replaced with “+” (#32 replaced by #43).
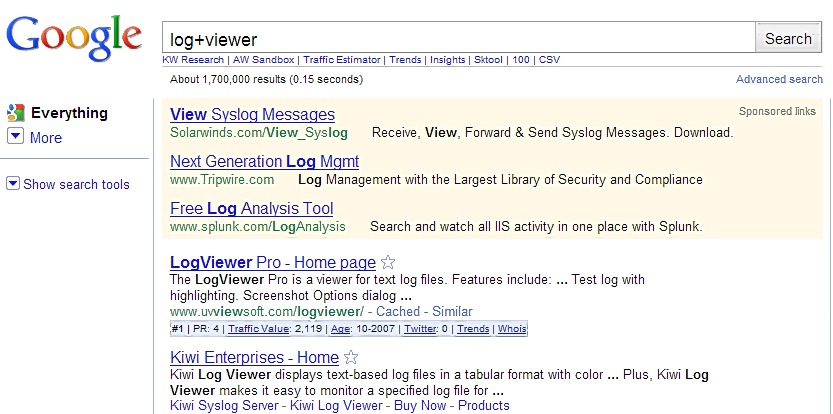
Search Engine Enhancement
Getting timely search engine coverage of a site means people can find things soon after you change or post them.
Linked pages get searched by most search engines following external links or manual URL submissions every few days or so, but they won’t find unlinked pages or broken links, and it is likely that the ranking and efficiency of the search is suboptimal compared to a site that is indexed for easy searching using a sitemap.
There are three basic steps to having a page optimally indexed:
- Generating a Sitemap
- Creating an appropriate robots.txt file
- Informing search engines of the site’s existence
Sitemaps
It seems like the world has settled on sitemaps for making search engine’s lives easier. There is no indication that a sitemap actually improves rank or search rate, but it seems likely that it does, or that it will soon. The format was created by Google, and is supported by Google, Yahoo, Ask, and IBM, at least. The reference is at sitemaps.org.
Google has created a python script to generate a sitemap through a number of methods: walking the HTML path, walking the directory structure, parsing Apache-standard access logs, parsing external files, or direct entry. It seems to me that walking the server-side directory structure is the easiest, most accurate method. The script itself is on sourceforge . The directions are good, but if you’re only using directory structure, the config.xml file can be edited down to something like:
<?xml version="1.0" encoding="UTF-8"?> <site base_url="http://www.your-site.com/" store_into="/www/data-dist/your_site_directory/sitemap.xml.gz" verbose="1" > <url href="http://www.your-site.com/" /> <directory path="/www/data-dist/your_site_directory" url="http://www.your-site.com/" default_file="index.html" />
Note that this will index every file on the site, which can be large. If you use your site for media files or file transfer, you might not want to index every part of the site. In which case you can use filters to block the indexing of parts of the site or certain file types. If you only want to index web files you might insert the following:
<filter action="pass" type="wildcard" pattern="*.htm" /> <filter action="pass" type="wildcard" pattern="*.html" /> <filter action="pass" type="wildcard" pattern="*.php" /> <filter action="drop" type="wildcard" pattern="*" />
Running the script with
python sitemap_gen.py --config=config.xml
will generate the sitemap.xml.gz file and put it in the right place. If the uncompressed file size is over 10MB, you’ll need to pare down the files listed. This can happen if the filters are more inclusive than what I’ve given, particularly if you have large photo or media directories or something like that and index all the media and thumbnail files.
The sitemap will tend to get out of date. If you want to update it regularly , there are a few options: one is to use a wordpress sitemap generator (if that’s what you’re using and indexing) which does the right thing and generates a sitemap using relevant data available to wordpress and not to the file system (a good thing) and/or add a chron script to regenerate the sitemap regularly, for example
3 3 * * * root python /path_to/sitemap_gen.py --config=/path_to/config.xml
will update the sitemap daily.
robots.txt
The robots.txt file can be used to exclude certain search engines, for example MSN if you don’t like Microsoft for some reason and are willing to sacrifice traffic to make a point, it also points search engines to your sitemap.txt file. There’s kind of a cool tool here that generates a robots.txt file for you but a simple one might look like:
User-agent: MSNBot % Agent I don't like for some reason Disallow: / % path it isn't allowed to traverse User-agent: * % For everything else Disallow: % Nothing is disallowed Disallow: /cgi-bin/ % Directory nobody can index Sitemap: http://www.my_site.com/sitemap.xml.gz % Where my sitemap is.
Telling the world
Search engines are supposed to do the work, that’s their job, and they should find your robots.txt file eventually and then read the sitemap and then parse your site without any further assistance. But to expedite the process and possibly enhance search results there are some submission tools at Yahooo, Ask, and particularly Google that generally allow you to add meta information.
Ask
Ask.com allows you to submit your sitemap via URL (and that seems to be all they do)
http://submissions.ask.com/ping?sitemap=http://www.your_site.com/sitemap.xml.gz
Yahoo
Yahoo has some site submission tools and supports site authentication, which means putting a random string in a file they can find to prove you have write-access to the server. Their tools are at
https://siteexplorer.search.yahoo.com/mysites
with submissions at
https://siteexplorer.search.yahoo.com/submit.php
you can submit sites and feeds. I usually use the file authentication which means creating a file with some random string (y_key_random_string.html) with another random string as the only contents. They authenticate within 24 hours.
It isn’t clear that if you have a feed and submit it that it does not also add a site, it looks like it does. If you don’t have a feed you may not need to authenticate the site for submission.
Google
Google has a lot of webmaster tools at
https://www.google.com/webmasters/tools/siteoverview?hl=en
The verification process is similar but you don’t have to put data inside the verification file so
touch googlerandomstring.html
is all you need to get the verification file up. You submit the URL to the sitemap directly.
Google also offers blog tools at
http://blogsearch.google.com/ping
Where you can manually add the feed for the blog to Google’s blog search tool.
ZoneMinder on FC7

Overview
Zone Minder Config ZoneMinder 1.22.3 on Fedora Core 7
There are useful instructions at this URL
Do a basic install of FC7.
- KDE seems to work better than gnome.
- Remove unnecessary SW to speed install (desktop stuff)
- Add Server and Development to get the right tools
- Add https://www.systutorials.com/additional-repositories-for-fedora-linux/ as an RPM source
- (via this link)
- Make sure the necessary holes are in the firewall at 80
Add necessary bits
yum install mysql-server mysql-devel php-mysql pcre-devel \
perl-DateManip perl-libwww-perl perl-Device-SerialPort \
perl-MIME-Lite perl-Archive-Zip
updating perl (some will be installed already)
perl -MCPAN -e shell
install Bundle::CPAN
reload CPAN
install Archive::Tar
install Archive::Zip
install MIME::Lite
install MIME::Tools
install DateTime
install Date::Manip
install Bundle::libnet
install Device::SerialPort
install Astro::SunTime
install X10
quit
FFMPEG install
Note that getting the FFMPEG libraries installed so they work is a nightmare. I followed these instructions and they seemed to work:
First add the x264 libraries and devel from livna via software manager
If the database hangs try
rm /var/lib/rpm/__db*
rpm --rebuilddb
yum clean all
svn checkout svn://svn.mplayerhq.hu/ffmpeg/trunk ffmpeg
cd ffmpeg/
./configure --enable-shared --enable-pp \
--enable-libx264 --cpu=pentium3 --enable-gpl
make
make install
nano /etc/ld.so.conf
add the line “/usr/local/lib”
ldconfig
System demons
chkconfig --add mysqld
chkconfig --level 345 mysqld on
chkconfig --level 345 httpd on
service mysqld start
service httpd start
add to /etc/sysctl.conf to increase shared memory limit
kernel.shmall = 134217728
kernel.shmmax = 134217728
Zoneminder Install
Check the latest version of zoneminder at https://web.archive.org/web/20110310142847/http://www.zoneminder.com:80/downloads.html
wget https://zoneminder.com/downloads/
tar xvfz ZoneMinder-1.22.3.tar.gz
cd ZoneMinder-1.22.3
patch it
https://web.archive.org/web/20110501001851/http://www.zoneminder.com:80/wiki/index.php/1.22.3_Patches
The configure command I used is:
./configure --with-webdir=/var/www/html/zm \
--with-cgidir=/var/www/cgi-bin ZM_DB_HOST=localhost\
ZM_DB_NAME=zm ZM_DB_USER=zmuser ZM_DB_PASS=zmpass \
CFLAGS="-g -O3 -march=pentium3" CXXFLAGS="-g -O3 \
-march=pentium3" --with-ffmpeg=/usr/bin \
--with-webuser=apache --with-webgroup=apache
putting a reasonable user name for “zmuser” and password for “zmpass”
make
make install
If make barfs with
/usr/local/src/ZoneMinder-1.22.3/src/zm_mpeg.cpp:284: undefined reference to `av_free(void*)'
try
”in src/zm_mpeg.h starting on line 26, add the lines with the + (removing the + of course) The other lines are just for reference and should be already in the file.” from this reference (lost to the void, alas).
nano src/zm_mpeg.h
#define ZM_MPEG_H
+extern "C" {
+#define __STDC_CONSTANT_MACROS
#include <ffmpeg/avformat.h>
+}
#if FFMPEG_VERSION_INT == 0x000408
Install scripts
install scripts/zm /etc/init.d/
chkconfig --add zm
Create and configure the ZoneMinder database
mysql mysql < db/zm_create.sql
mysql mysql
at the mysql prompt:
grant select,insert,update,delete on zm.* to \
'zmuser'@localhost identified by 'zmpass';
quit
mysqladmin reload
GO!
service zm start
you should get a nice green [OK].
http://127.0.0.1/zm
Black Screen? Go Faster?
No php?
If you have issues make sure you have installed apache php and perl modules.
IJG SIMD jpeg should double performance.
http://cetus.sakura.ne.jp/softlab/jpeg-x86simd/jpegsimd.html#source
* requires nasm which wasn’t installed. Use package manager.
wget http://cetus.sakura.ne.jp/softlab/jpeg-x86simd/sources/jpegsrc-6b-x86simd-1.02.tar.gz
tar xvfz jpegsrc-6b-x86simd-1.02.tar.gz
cd jpeg-6bx
./configure --enable-shared --enable-static
nano Makefile
* Change the CFLAGS from O2 to O3 and add
-funroll-loops -march=pentium3 -fomit-frame-pointer
make
make test
make install
identify the libraries to the system
ldconfig
I also copied the installed files from /usr/local/bin to /usr/bin:
cp /usr/local/bin/cjpeg /usr/bin/cjpeg
cp /usr/local/bin/cjpeg /usr/bin/cjpeg
cp /usr/local/bin/cjpeg /usr/bin/cjpeg
cp /usr/local/bin/cjpeg /usr/bin/cjpeg
cp /usr/local/bin/cjpeg /usr/bin/cjpeg
/etc/init.d/zm restart
NetPBM resizes the JPEGS and faster is better: compile and install
cd /usr/src
svn checkout https://netpbm.sourceforge.net/ netpbm
cd netpbm
/usr/src/netpbm/configure
Answer the questions (GNU and then defaults – I didn’t have TIFF or VGA libs, so “none”)
vi Makefile.config
I added -march=pentium3 to the CFLAGS at the end of the file
make
make package
/usr/src/netpbm/installnetpbm
accept defaults
cabozola install
* package add Ant (it needs ant, but it wasn’t installed by default)
cd /usr/src
wget https://web.archive.org/web/20220526174548/http://www.charliemouse.com/code/cambozola/cambozola-latest.tar.gz
tar xvfz cambozola-latest.tar.gz
cp /usr/src/cambozola-0.68/dist/cambozola.jar /var/www/html/zm
chmod 775 /var/www/html/zm/cambozola.jar